v0.1版本说明:本文发在主站上之后,站友们经常评论代码跑着有问题。经过和lijian大哥等人进行咨询,自己也摸索了一些之后,发现了之前代码非常多的漏洞。因此,给广大站友带来了困扰。在这里我表示万分的抱歉。最近邮箱中收到让我整理代码的需求越来越多。我也非常想整理下,但是由于工作也非常繁忙,所以很难抽出时间。前两天说5.1期间会整理一下代码发出来。但是事实上因为5.1小长假期间我可能无法上网,导致无力更新代码。所以今晚抽时间对代码进行了简单的修改。对本文也进行了一些调整。目前的状况是,基本上到生成待分析的语料库已经没有问题了。聚类分析的模型可以跑出来,但是最终的图画不出来。我暂时也没能找到原因。所以进一步的调整可能要等到5.1过完以后再抽时间来做了。这篇文章我会负责到底的哈。(20130429)
完整代码如下:weibo_analysis
—————————–分割线————————————————-
自从lijian大哥的Rweibo包问世以来,便成了R爱好者们获取新浪微博数据的最为重要的工具。在该包的中文主页上,作者对如何连接新浪微博的API,获取授权,并以此为基础开发应用的原理讲解的非常清楚。对于我这种连基本的网页开发神马原理都一点也不清楚的菜鸟来说,Rweibo是一种非常趁手的获取微博数据的工具。
有了获取数据的工具,对于中文文本分析来说,最重要的是分词。这里使用的分词算法来自中科院 ictclas算法。依然是沾了lijian大哥Rwordseg的光,直接拿来用了。
有了这两样利器,我们便可以来分析一下新浪微博的数据了。我选取的话题是最近热映的国产喜剧电影《泰囧》,在微博上拿到了998条和“泰囧”有关的微博文本。代码如下(以下代码不能直接执行,请首先阅读链接中Rweibo的关于授权帮助文档):
#关键词搜索并不需要注册API
require(Rweibo)
#registerApp(app_name = "SNA3", "********", "****************")
#roauth <- createOAuth(app_name = "SNA3", access_name = "rweibo")
res <- web.search.content("泰囧", page = 10, sleepmean = 10,sleepsd = 1)$Weibo
获取了数据之后,首先迫不及待对微博文本进行分词。代码如下(Rwordseg包可以在语料库中自助加入新词,比如下面的insertWords语句):
require(Rwordseg)
insertWords("泰囧")
n = length(res[, 1])
res = res[res!=" "]
words = unlist(lapply(X = res, FUN = segmentCN))
word = lapply(X = words, FUN = strsplit, " ")
v = table(unlist(word))
v = sort(v, decreasing = T)
v[1:100]
head(v)
d = data.frame(word = names(v), freq = v)
完成分词之后,我们最先想到的,便是对词频进行统计。词频排名前53的词列表如下(这个词频是我人工清理过的,但是只删除了一些符号):
泰囧 1174 一代宗师 87 时候 53 生活 44 娱乐 35 成功 30
电影 385 看过 70 影片 52 文化 43 但是 33 王宝强 30
票房 306 上映 68 今天 51 影院 43 分享 33
囧 275 泰国 68 喜剧 51 炮轰 40 发现 32
笑 192 感觉 62 导演 49 电影院 38 故事 32
俗 188 观众 61 好看 49 排 38 光线 32
十二生肖 123 可以 60 喜欢 49 哈哈 37 国民 32
什么 104 大家 59 上海 48 兽 37 时间 32
中国 102 教授 56 现在 48 水平 37 哈哈哈 31
徐峥 90 11亿 54 搞笑 47 需要 35 逼 30
从中我们可以看出一些东西。比如说这部电影的口碑似乎还不错,此外某教授对其的炮轰也引发了不少得讨论。另外,同档期的另外两部电影(一代宗师,十二生肖)也经常和它同时被提及(这是否会对某些搞传播和营销的人带来一些启发,联动效应之类的,纯数个人瞎说)。 词云展示是不可少的,展示频率最高的150个词(这里我实现把分词的结果存放在了txt文件中,主要目的是为了节省内存):
require(wordcloud)
d = read.table("wordseg.txt")
dd = tail(d, 150)
op = par(bg = "lightyellow")
# grayLevels = gray((dd$freq)/(max(dd$freq) + 140))
# wordcloud(dd$word, dd$freq, colors = grayLevels)
rainbowLevels = rainbow((dd$freq)/(max(dd$freq) - 10))
wordcloud(dd$word, dd$freq, col = rainbow(length(d$freq)))
par(op)

下面做一些相对来说比较专业的文本挖掘的工作。主要目的是对这998条微博进行聚类。聚类里最核心的概念是距离。将距离比较靠近的数据聚为一类就是聚类。对于文本来说,如何定义距离呢?也就是说我如何来衡量微博与微博之间的距离。这涉及到了文本挖掘最基本的概念,通过建立语料库,词频-文档矩阵,来衡量文档之间的相关性,从而衡量文档之间的距离之类的。详情请参看刘思喆大哥R语言环境下的文本挖掘。下面使用PAM算法,对998条微博进行聚类。看看能不能得出一些什么有意思的结果。
PAM算法全称是Partitioning Around Medoids算法。中文翻译为围绕中心点的划分算法。该算法是基于相异矩阵的(dissimilarity matrix)。也就是说,这个算法对于样本的距离度量是基于相异矩阵的。而不是基于通常使用的距离。因此,这个算法相对来说比较稳健(比起kmeans)。该算法首先计算出k个medoid,medoid的定义有点绕口。基本上的想法就是它和同一聚类中的其他对象的相异性是最小的。也就是说,同一个聚类的对象都是围绕着medoid的。和它的平均相异程度最小。找到这些medoid之后,再将其他样本点按照与medoid的相似性进行分配。从而完成聚类。R语言中的fpc包实现了这种算法,并且给出了非常有意思的聚类图。
首先,载入tm包,建立语料库,建立词频矩阵:
#4.建立语料库
require(tm)
#先生成一个语料库,来清理一下微博的文本
weiboCorpus <- Corpus(VectorSource(res))
#删除标点符号
weiboCorpus <- tm_map(weiboCorpus,removePunctuation)
#删除数字
weiboCorpus <- tm_map(weiboCorpus,removeNumbers)
#删除URL,使用了一点正则表达式
removeURL <- function(x) gsub("http[[:alnum:]]*","",x)
weiboCorpus <- tm_map(weiboCorpus, removeURL)
#再次分词
weiboData <- as.data.frame(weiboCorpus)
weiboData <- t(weiboData)
weiboData <- as.data.frame(weiboData)
#head(weiboData) #再次加入一些词
insertWords(c("泰囧","十二生肖","一代宗师","黄渤","人在囧途","人再囧途","三俗"))
weiboData$segWord <- segmentCN(as.matrix(weiboData)[,1])
#head(weiboData)
#形成了一个data.frame--weiboData,第一个变量为微博内容本身,第二个变量为分词的结果
#再次形成一个语料库,用来做更进一步的分析
weiboCorpusForAnys <- Corpus(DataframeSource(weiboData))
#其实这个时候再画一个词云,可能效果会更好些
#目前代码运行到这一步都是没有问题的。我反复试了几次了。
#下面的fpc做聚类,最终图形无法展示出来。回头我5.1放假回来会扣一下的。
#5.pam算法对微博进行聚类分析
require(fpc)
weiboTDMatrix control = list(wordLengths = c(1, Inf)))
TDMforCluster <- removeSparseTerms(weiboTDMatrix,sparse=0.9)
MatrixForCluster <- as.matrix(TDMforCluster)
MatrixWeiboForCluster <- t(MatrixForCluster)
pamRes <- pamk(MatrixWeiboForCluster,metric="manhattan")
k <- pamRes$nc
k
pamResult <- pamRes$pamobject
pamResult$clustering
layout(matrix(c(1,2),2,1))
plot(pamResult,color=F,labels=4,lines=0,cex=0.8,col.clus=1,col.p=pamResult$clustering)
layout(matrix(1))
结果我们将微博分成了两类:
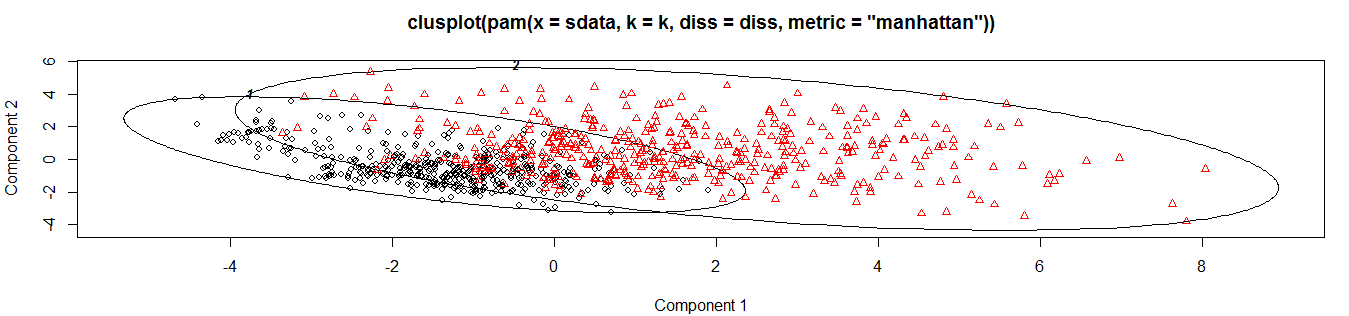
当然了,从这个图,你很难看出点什么有益的信息,就是图个好看。我们不妨来看看被分成两类的微博都分别说了些什么。具体看到过程和解读因人而异,这里也没什么代码要列出来。我只说一些我看到的,不保证是对的。
两个聚类中的微博讨论的问题不同,第一类讨论的是看了泰囧的心情,比如开心,高兴抑或难过之类的。比如:
“哈哈哈二到無窮大.大半夜的我這二逼在家看泰囧.笑到爸爸起床罵我..不好意思咧.實在沒忍住”
“时间滴答滴答的走我知道我在想着一个人看泰囧片头的时候熟悉的名字我一下子愣住了我想我是在乎了这样的夜里我难过”
“大半夜睡不着觉一个人在家看盗版泰囧突然觉得很凄惨”
“我们一起吃牛排一起坐轮渡一起看金门一起去乐园一起吃牛排一起看大海一起坐公交一起啃鸡爪一起过圣诞一起看泰囧一起去鼓浪屿一起打的绕厦门岛一起在酒店吃早餐一起在一张大床上睡觉一起吃烤鱼一起在大排档吃肉一起在KFC买了对辣翅一起爬鼓山一起抱着对方说我爱你”
这一类微博本身不够成对电影的评价,电影是这些博主生活的一部分,或悲或喜,电影只是陪衬。
第二类微博,则集中于对电影的评价,褒贬不一,比如:
“搜索一代宗师发现十个里面九个说不好看上回的泰囧微博上都是说怎么怎么好笑结果去影院一看大失所望还没有赵本山演的落叶归根幽默和寓意深远纯属快餐式电影其实好的事物往往具有很大的争议性就比如John.Cage.的有的人觉得纯属扯淡有的人却如获至宝我想王家卫的电影也是如此”
“应该看第一部人在囧途比泰囧好看太多了第一部我从头看到尾很有意思第二部看分钟掐断沉闷没什么笑点”
“泰囧实在好看极了又搞笑又感动让我哭笑不得真心推荐晚安啦.我在”
“发表了博文.影评人再囧途之泰囧..首映没有赶上好多朋友强烈向我推荐推荐理由很具有唯一性笑到我抽搐.笑成了这部电影唯一的标签但是这已经足够了.在好莱坞大片冲击欧洲小资”
从我的解读来看,微博大致分为这两类,如果进一步分析,也可以将发微博的人分成两类。一类可能相对感性,单纯,生活中的高兴或者快乐,会表现在微博中。电影只是作为引发他们情绪的一件事儿被提及。而另一类人,相对比较理性,喜欢评论,喜欢写博客写影评之类。电影在他们的心中,是被评价的对象。当然,这两类人或者两类微博会有很多部分是重叠交替的。这是非常正常的现象,就像人也有理性和感性的两个面。
结语:本文仅仅是对微博数据的初步探索。感谢lijian大哥的两个包,我想,这两个包将改变微博数据分析的面貌。更多R语言爱好者将通过这两个包发挥他们的热情,来更多的挖掘微博中有价值的信息。另外,笔者从未深入研究过文本挖掘。望看官拍砖时手下留情。
敬告各位友媒,如需转载,请与统计之都小编联系(直接留言或发至邮箱:editor@cos.name),获准转载的请在显著位置注明作者和出处(转载自:统计之都),并在文章结尾处附上统计之都微信二维码。

发表/查看评论