微博,这一新生代大规模杀伤性社交武器近年来迅速在国内走红,其来势之汹,范围之广,威力之猛当不可小觑。通过它,我们不仅能第一时间八卦到身边柴米油盐、鸡毛蒜皮的小事儿,而诸如家国天下、业内前沿的大事记也难以逃过公众的法眼。
这样迅捷高效的信息传播是怎样做到的呢?相信每一个微博控都能如数家珍的道出自己心仪的几位微博名人们,不妨就从那些微博名人们入手,看看这些名人们身边的故事。
1、信息采集
信息采集,说白了就是数据爬取。还好,这些名人们可是早就榜上有名了,可以用 XML 包的 readHTMLTable 函数爬下来风云榜上来自体育、财经、传媒、科技 and so on 的风云人物的微博信息,存为数据集。
以 sports 数据集为例,代码如下:
library(XML)
# get data from web
webpage <-'http://data.weibo.com/top/influence/famous?class=29&type=day'
tables <- readHTMLTable(webpage,stringsAsFactors = FALSE)
sports=tables[[1]][,c(1,2,3,6)]
names(sports)=c("rank","name","influence","description")
这样,我们就获取了这些名人们的微博大名。
接下来,顺藤摸瓜,根据李舰老师 Rweibo 包(0.2-7 版本)的web.search.user()以及web.user_timeline()函数就能得到他们的微博文本信息,这里考虑到可能会抓取失败的情形(教练我想要个高级权限 T^T),得到如下代码 (name 为之前得到各个):
name=c(sports$name,entertain$name,economic$name,media$name,literature$name,fashion$name,IT$name,education$name)
res_719=list()
for (i in 1:length(name))
{
show(i)
res_719[[i]] <- tryCatch({
user=web.search.user(name[i])
a=web.user_timeline(roauth, uid=user$uid, pages = 1:3)
}, error = function(err) {
# warning handler picks up where error was generated
print(paste("MY_ERROR: ",err))
user=0
a=0
return(a)
}, finally = {
print(dim(a))
}) # END tryCatch
}
最后成功抓取的微博名人有 338 个,让我们看看他们都是谁:
aa=sapply(res_719,function(x) {return(!is.null(dim(x)))})
weibo=res_719[aa]
name=name[aa]
截取部分显示如下:

2、数据清洗
通过 Rwordseg 包,我们可以对中文的微博内容进行分词(由于名人大多为汉语用户,这里为方便后文处理,我去除了英文的词汇),首先需要安装需要的词典以及去除中文停词:
library(Rwordseg)
installDict("F:/weibo/data/搜狗标准词库.scel", dictname = "biaozhun.scel",
dicttype = c("scel"))
insertWords("微博")
stopwords=readLines("your_home_path/CH_stopwords.txt")
接下来对微博内容去除链接、标点、数字、人名、停词等噪音信息,并以每位名人的逐条微博为单位保存。同时鉴于汉语的表意单元只保存了双字节及以上的汉语词汇,处理代码如下:
Clean.Weibo.list <- function(x)
{
weibos=c(x$Weibo,x$Forward)
weibos=weibos[!is.na(weibos)]
weibos1=gsub("(http://[a-z\\.\\/\\-0-9\\(\\)\\=]+)|(@[\u4e00-\u9fa5\\w]+\\s)|(//@[^\\s]+:)"," ",
weibos,
perl=T)
weibos1=gsub('[[:punct:][:digit:]a-zA-Z\\-]+'," ",weibos1)
seg_weibo=segmentCN(weibos1)
seg_weibo1=lapply(seg_weibo,
function(x)
{y=setdiff(x,stopwords);z=y[y!=""&nchar(y)>=2];
if (length(z)==0) return(0)
return(table(z))})
ll=sapply(seg_weibo1,function(x) return(all(x==0)))
if (all(ll)) return(0)
return(seg_weibo1[!ll])
}
weibo_doc1=lapply(weibo,Clean.Weibo.list)
ll=sapply(weibo_doc1,function(x) {return(is.list(x))})
weibo_doc1=weibo_doc1[ll]
name=name[ll]
去噪音后,最终保存的名人数为 335 个。
不过,囿于本人机器的运算能力,在这里以名人为单位对其微博进行抽样汇总:
Weibo.sample <- function(x)
{
l=length(x)
if (l<10) return(x)
ind=sample(1:l,floor(l/3))
return(x[ind])
}
weibo_doc1_sample=lapply(weibo_doc1,Weibo.sample)
weibo_doc2=unlist(weibo_doc1_sample,recursive=F)
最终得到的微博个数为 20767 个。
3、物以类聚
俗话说的好,物以类聚,人以群分。如果你是个数据分析发烧友,那么你可能经常将 “统计”、“机器学习”、“R 语言” 这些词汇挂在嘴边儿;而同时你又有可能是一名体育爱好者、车迷甚至于伪文艺青年。
那么,怎样探寻汉语词汇之间关联关系以及表征每个人的兴趣爱好特征呢?我不禁想起了 rickjin 老师的 LDA 数学八卦系列,不妨用 Blei 大神的 topicmodel 来小试牛刀吧~
为了进一步去除噪音,首先去除某些 tf-idf 较低的词汇(这里去除的是 quantile 中小于 0.01 的词汇),并保存文档 - 词频矩阵(Doc-word Matrix):
library(slam)
library(tm)
library(topicmodels)
get.col <- function(com)
{
col=unique(unlist(lapply(com,function(x) names(x))))
return(col)
}
get.mat <- function(col,com,M=F)
{
nrow=length(com);ncol=length(col)
ijv=NULL
for (i in 1:length(com))
{
cat(i,"\n")
ii=which(is.element(col,names(com[[i]])))
ijv=rbind(ijv,cbind(i,ii,as.vector(com[[i]])))
}
if (M==T)
mat=sparseMatrix(ijv[,1],ijv[,2],ijv[,3],
dims=c(nrow,ncol))
else
mat=simple_triplet_matrix(ijv[,1],ijv[,2],ijv[,3], dimnames = NULL)
colnames(mat)=col
return(mat)
}
col_long=get.col(weibo_doc2)
weibo_mat_long=get.mat(col=col_long,weibo_doc2,M=F)
dtm <- as.DocumentTermMatrix(weibo_mat_long,weighting =weightTf,
control = list(stemming = TRUE, stopwords = TRUE, removePunctuation = TRUE,tolower=T))
term_tfidf <- tapply(dtm$v/row_sums(dtm)[dtm$i], dtm$j, mean) *
log2(nDocs(dtm)/col_sums(dtm > 0))
ll=term_tfidf>=quantile(term_tfidf,0.01)
dtm <- dtm[,ll]
dtm <- dtm[row_sums(dtm) > 0,]
如何选一个合适的 topic 数目呢?可以分别选用 perplexity 以及 loglikelihood 指标分别求取最佳的 topic 数目,代码如下:
smp <-function(cross=5,n,seed)
{
set.seed(seed)
dd=list()
aa0=sample(rep(1:cross,ceiling(n/cross))[1:n],n)
for (i in 1:cross) dd[[i]]=(1:n)[aa0==i]
return(dd)
}
selectK <-function(dtm,kv=seq(5,60,5),SEED=2013,cross=5,sp)
{
per_gib=NULL
log_gib=NULL
for (k in kv)
{
per=NULL
loglik=NULL
for (i in 1:cross)
{
te=sp[[i]]
tr=setdiff(1:nrow(dtm),te)
Gibbs = LDA(dtm[tr,], k = k, method = "Gibbs",
control = list(seed = SEED, burnin = 1000,
thin = 100, iter = 1000))
per=c(per,perplexity(Gibbs,newdata=dtm[te,]))
loglik=c(loglik,logLik(Gibbs,newdata=dtm[te,]))
}
per_gib=rbind(per_gib,per)
log_gib=rbind(log_gib,loglik)
}
return(list(perplex=per_gib,loglik=log_gib))
}
sp=smp(n=nrow(dtm),seed=2013)
system.time((gibK=selectK(dtm=dtm,kv=seq(5,60,5),SEED=2013,cross=5,sp=sp)))
m_per=apply(gibK[[1]],1,mean)
m_log=apply(gibK[[2]],1,mean)
k=seq(5,60,5)
plot(x=k,y=m_per)
k[which.min(m_per)]
plot(x=k,y=m_log)
k[which.max(m_log)]
选取 50 作为合适的 topic 数目(这一部分运行成本较高,慎)。以 Gibbs sampling 的 inference 方法为例,让我们看看每个 topic 中的高频词分别是什么:
SEED <- 2013
VEM = LDA(dtm, k = k, control = list(seed = SEED))
VEM_fixed = LDA(dtm, k = k,
control = list(estimate.alpha = FALSE, seed = SEED))
CTM = CTM(dtm, k = k,
control = list(seed = SEED,
var = list(tol = 10^-4), em = list(tol = 10^-3)))
Gibbs = LDA(dtm, k = k, method = "Gibbs",
control = list(seed = SEED, burnin = 1000,
thin = 100, iter = 1000))
terms(Gibbs,5)

可以看到它们之中有关于电子产品的(手机、电脑、游戏)、有关于热点新闻的(首都机场爆炸、雅安地震、城管打死瓜农)、有娱乐新闻的、也有各种活动有奖转发的。接下来,用训练好的 topicmodel 做 inference,这里我们需要的是以人为单位的 document:
## inference
Clean.Weibo <-function(x)
{
weibos=c(x$Weibo,x$Forward)
weibos=weibos[!is.na(weibos)]
weibos1=gsub("(http://[a-z\\.\\/\\-0-9\\(\\)\\=]+)|(@[\u4e00-\u9fa5\\w]+\\s)|(//@[^\\s]+:)"," ",
weibos,
perl=T)
seg_weibo=unlist(segmentCN(weibos1))
seg_weibo1=setdiff(seg_weibo,stopwords)
seg_weibo2=gsub('[[:punct:][:digit:]a-zA-Z\\-]+',"",seg_weibo1)
seg_weibo2=seg_weibo2[seg_weibo2!=""&nchar(seg_weibo2)>=2]
if (length(seg_weibo2)==0) return(0)
return(table(seg_weibo2))
}
weibo_doc=lapply(weibo,Clean.Weibo)
ll=sapply(weibo_doc,function(x) {return(!all(x==0))})
weibo_doc=weibo_doc[ll]
col=get.col(weibo_doc)
weibo_mat=get.mat(col=col,weibo_doc,M=F)
dtm <- as.DocumentTermMatrix(weibo_mat,weighting =weightTf,
control = list(stemming = TRUE, stopwords = TRUE, removePunctuation = TRUE,tolower=T))
dist=posterior(Gibbs,newdata=dtm)[[2]]
不妨选取几个有代表性的 topic(这里我去除了一些副词、连接词以及表征时间的词汇代表的 topic),做聚类热力图。与单纯用词频文档聚类而得的热力图对比如下:


可见 topicmodel 起到了一定的提取特征,去粗取精的功效。
不妨拿名人们在所选的 topic 上的得分做一下聚类分析。这里按照每个 topic 中的高频词对不同 topic 进行命名,选取类别数为 10(最大类中的名人个数 <=60),对每一类中的均值 topic 得分做均值图:
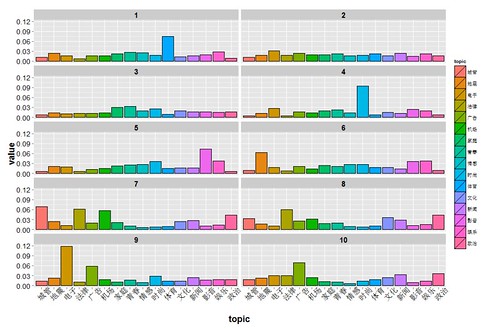
代码如下,每一类的名人保存于 hc_name 中:
colnames(dist1)=c("电子","娱乐","城管","地震","新闻","机场","广告","影音",
"体育","政治","时尚","文化","法律","情感","青春","家庭")
k=2
while(max(sapply(rect.hclust(hc, k=k),length))>60)
{k=k+1;
show(k)}
hc_res=rect.hclust(hc, k=10)
hc_mean=lapply(1:length(hc_res),function(x)
{return(data.frame(group=as.factor(x),topic=as.factor(colnames(dist1)),value=apply(dist1[hc_res[[x]],],2,mean)))})
hc_mean_d=do.call(rbind,hc_mean)
p <- ggplot(hc_mean_d, aes(x=topic,y=value,fill=topic))
p= p +geom_bar(stat="identity",col="black")
p <- p+ facet_wrap(~ group, ncol = 2,drop=F)
p=p + theme(axis.text.y = element_text(size=rel(1.5),colour="black"),
axis.text.x = element_text(size=rel(1.7),colour="black",angle=45),
axis.title.y = element_text(size = rel(1.5), angle = 90,face="bold"),
axis.title.x = element_text(size = rel(1.5),face="bold"),
plot.title = element_text(size = rel(1.8),face="bold"),
strip.text = element_text(size = 15, face="bold",
hjust = 0.5, vjust = 0.5))
p
hc_name =lapply(hc_res,function(x) {return(name[x])})

后记:
整个过程中有很多不甚明朗的地方,我且谨列几条如下:
(1) doc 应该怎样定义,是应该以每人为单位训练 topicmodel 还是应该以每条微博为单位?经过比较我发现以每条微博为单位训练的 topicmodel 中的每个 topic 的 term 类别更加一致;因此我选择了以微博为 doc 单位训练,并以人为 doc 单位做 inference;不过我没有找到关于这个问题更详细的 reference,看到的几篇关于 twitter、microblog 的 topicmodel 应用也是用逐条微博作为处理单位。
(2)不同的估计方法之间有什么区别?R 包提供的有 VEM、Gibbs、CTM 等,这里没有做细节的比较,本文后文结果全部以 Gibbs 估计结果为主。
(3)topicmodel 适不适合做短文本的分析?sparsity 会带来怎样的问题?实际上以逐条微博为 doc 单位分析正会导致 sparsity 的问题,不过我还没意识到它潜在带来的问题。
(4)中文的文本处理感觉很捉急啊…… 除了分词之外的词性标注、句法分析、同义词等等都没有专门处理的 R 包,本文也仅做了初步的处理。
(5)最后的聚类效果不仅仅考虑名人的专业领域,也考虑了其生活中的情感状态、爱好兴趣等,是一个综合的结果,选取不同的专业领域可以通过选取不同 topic 做聚类分析而得。
备注
原文链接:微博名人那些事儿 ,转载请注明出处。
关于作者
朱雪宁曾任编辑部主编。复旦大学大数据学院助理教授。北京大学光华管理学院商务统计系博士, 宾州州立大学统计博士后。研究上关注社交网络分析, 时空数据建模等;狗熊会创始团队成员。 |  |
敬告各位友媒,如需转载,请与统计之都小编联系(直接留言或发至邮箱:editor@cos.name),获准转载的请在显著位置注明作者和出处(转载自:统计之都),并在文章结尾处附上统计之都微信二维码。

发表 / 查看评论