**作者:**杜晓梦(百分点信息科技),唐晓密(百分点信息科技),张文学(百分点信息科技)
摘要:近年来,深耕国产手机市场多年的某手机及家电品牌厂商推出了旗下智能手机独立子品牌,之后不定期推出该品牌的系列新产品。随着智能手机竞争日趋激烈,新机上市时,如何从国产智能手机大军中脱颖而出,并获得消费者的青睐,就需要一套行之有效的适合市场的营销策略。本文主要总结此智能手机品牌利用大数据分析与数据挖掘技术,辅助其实现新品上市营销的策略过程。首先,在中国手机用户市场进入换机时代背景下,本文分析了其新机上市前如何加强对老客户的深度营销。主要依据该手机及家电厂商手机、电视、冰箱、洗衣机、空调、移动电源、空气净化器等品类线上电商和线下销售公司的客户交易数据,提取了用户的行为特征,包括识别这个终端消费用户的购买频次,消费的品类,价格承受度等,运用关联规则模型,度量这个新品手机和其他品类的相似性。结合购买概率预测、产品生命周期预测等模型,输出目标群体的营销列表,找到整个老用户群体里有可能去购买新品手机的用户群体,并对购买概率进行排序,最终设计具有针对性一些相关联的深度营销计划。其次,在社会化媒体高速发展的背景下,本文阐述了其新机上市前如何进行微博营销推广。一是介绍了如何通过构建行业微博影响力指数模型,甄别出最有影响力的行业微博,有效传播品牌和产品。二是介绍了如何使用SNA社会网络模型,识别意见领袖,通过影响意见领袖,影响大多数追随者。三是介绍了如何采用文本分析建模,定位微博上想买新品手机及相关竞品的受众,以便进行精准营销。本文结合老用户营销和微博营销中的数据分析、模型建立与业务实施等方面,介绍了某智能手机品牌新品上市的全流程。
关键词:AHP方法、关联规则、SNA、SVM
一、研究背景
(一) 智能手机营销环境分析
-
智能手机行业增速放缓,国产手机厂商竞争空前激烈
TrendForce数据显示,2015年,全球智能手机出货量为12.9亿部,较上年同期增长10.3%。相比前几年的行业快速增长有所放缓。其中,中国地区的手机品牌合计出货量为5.4亿部,占全球比重超过四成,且7个品牌进入全球智能手机出货量TOP10。国产厂商中,华为出货量跻升前三,2015年同比增长49.4%;小米市场占有率为5.6%,较上年提升0.4个百分点;联想收购摩托罗拉智能手机业务后,2015年出货量同比下降24.6%,市场占有率也由上年的7.9%下降至5.4%;TCL智能手机市场占有率有所提升,由上年的第九位晋升至第七位;OPPO和VIVO首度上榜,市场占有率均达3%以上;中兴2015年表现一般,市场占有率与上年持平。产量的上升,意味着手机市场竞争空间加剧,现阶段智能手机品牌厂商的生存空间相互挤压严重。
表1 全球前10大智能手机排名
| 排名 |
| 公司 |
| 1 |
| 2 |
| 3 |
| 4 |
| 5 |
| 6 |
| 7 |
| 8 |
| 9 |
| 10 |
| Others |
| 智能手机出货量总计(部) |
数据来源:市场研究机构TrendForce
-
手机电商渠道迅速崛起,线上与线下营销结合成趋势
赛迪发布的《2015年中国手机市场回顾与展望》显示,2015年,国内手机线上渠道占比升至30.3%,手机独立店、手机连锁店、家电卖场、运营商营业厅四者合计占比56.9%。越来越多的手机厂商不再单独依赖线下渠道促销或维护客户,而是针对线上和线下渠道用户制定不同的营销措施,进一步提高用户体验。比如带有互联网基因的乐视、小米、荣耀、TCL么么哒等都在积极寻求线上和线下的渠道融合,进而深化线上和线下的营销策略。
-
国内新增市场转变为换机市场,把握老用户营销至关重要
国家运行监测协调局数据显示,2015年底,移动电话用户合计1,305,738,000户,比上年末净增19,645,000户,移动电话普及率为95.5部/百人。现在的新增手机市场已转变为换机市场,如何针对老客户的营销成为手机厂商关注的焦点。换机对用户体验提出了更高的要求,一些手机厂商纷纷基于用户换机需求开展了智能手机精准营销。比如构建各品类跨界营销、终端生命周期研究、终端使用习惯研究,以及整合用户偏好信息,采取针对性营销策略。
-
社会化媒体蓬勃发展,微博营销成为智能手机厂商营销的主战场之一
由于微博具有自媒体属性、社交性和大众性等特点,微博营销优势日益凸显。微博受众广泛,用户量日益剧增。新浪微博2015年发布的第三季度财报显示,截止2015年9月30日,微博月活跃用户数已经达到2.12亿人,较上年同期增长48%。智能手机厂商可通过微博更加有效找到目标受众,从而实现精准营销。此外,也可与具有话语权的行业微博、意见领袖等合作,迅速凝聚微博用户强大关注,实现品牌病毒再扩散,从而推动更多微博用户的关注与传播。
(二) 上市营销业务背景
某款新机将要上市,价格预期千元左右。新机上市前夕,我们制定了两个营销目标,一是增加销量,新机官网预约量、抢购量达到一定数量。一方面,针对有意向购买新机的老用户,短信推送营销活动信息;另一方面,针对微博潜在购买用户,由运营人员发私信推送营销活动信息。二是扩大品牌知名度。以微博作为传播的核心阵地,通过找到最有影响力的行业微博以及个人意见领袖,以“内容+事件”为核心,促进新机病毒再扩散。营销预期目标为新机手机品牌及新机的知名度进一步增强,包括新浪微博总转发量、总搜索量、话题进入当日热门话题榜排名、百度指数峰值等大幅增加。
(三) 研究方法介绍
-
老用户营销列表建模
老用户营销列表的生成,依据该手机及家电厂商手机、电视、冰箱、洗衣机、空调、移动电源、空气净化器等品类线上电商旗舰平台和线下门店的客户交易数据,一是从已购手机的用户中,筛选出购买新机倾向性较高的用户列表。主要依据识别终端消费者用户的购买频次、价格承受度、购买时间等特征,结合产品生命周期预测,输出购买新机概率较高的目标群体。二是从购买手机以外的其他品类老客户中,找到购买概率较高的用户。主要运用关联规则模型,度量这个新品手机和其他品类的相似性。通过对用户特征的过滤,锁定目标用户群体。通过大数据建模分析,对这两部分用户购买新机的可能性进行预测,从而聚焦有购买新机需求的用户。
-
微博影响力评估模型
微博影响力评估模型,既包括行业微博影响力指数模型,也包括SNA社会网络分析模型,目的是找到与手机相关的具有话语权的行业微博,以及具有影响力的个人微博,以便引导新机内容和事件的快速传播。
行业微博影响力指数模型,主要基于分类下的企业蓝V微博影响力数据,包括原创博文数、转发博文数、点赞数、评论数、转发数等指标,测算综合指数。第一步,对原始数据进行清洗,并将原始数据进行标准化处理,原始数据转换成无量纲指标测评值,保证各指标值都处于同一个数量级别上,可以进行综合测评分析,并将数据结果转化为1-100之间。第二步,运用层次分析法确定权重。层次分析法(Analytic Hierarchy Process,AHP)是美国运筹学家T.L Saaty于20世纪70年代提出的一种实用的多准则决策方法。它是一种将决策者对复杂系统的决策思维过程模型化、数量化的过程。运用这种方法,决策者将复杂问题层次化,即分解为若干层次和若干因素,形成一个多层分析结构模型,并在各因素之间进行简单的比较和计算,就可以得出不同因素重要性程度的权重,为最佳方案的选择提供依据。第三步,运用综合递阶加权方法测算各行业微博影响力指数。即将各指标下分数与权重相乘,再将各个行业微博的所有指标分数求和得到行业微博影响力指数评分,最终获得影响力最强的15个蓝V行业微博。
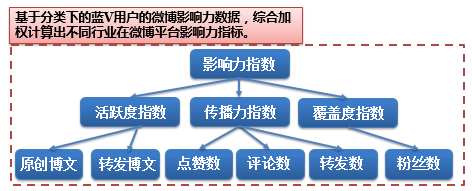
图1 行业微博影响力指数模型
SNA社会网络分析模型,基于个人微博用户发帖和回帖数据,识别意见领袖和活跃分子。社会网络分析法是一种社会学研究方法,社会学理论认为社会不是由个人而是由网络构成的,网络中包含结点及结点之间的关系,社会网络分析法通过对于网络中关系的分析探讨网络的结构及属性特征,包括网络中的个体属性及网络整体属性,网络个体属性分析包括出度、入度、点的中间中心度等;网络的整体属性分析包括小世界效应,小团体研究,凝聚子群等。本文通过对入度、中间中心度等指标测算出意见领袖,并通过逻辑回归模型进行验证。
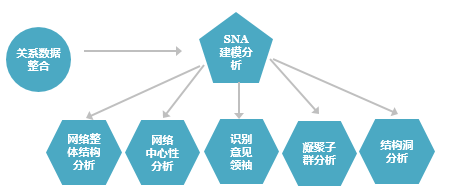
图2 SNA社交网络模型分析流程
-
微博文本分析建模
微博文本分析方法,主要基于微博带小米、华为、酷派、努比亚、联想、vivo、一加、魅族、金立、TCL、OPPO等关键词内容的抓取数据。本文采用的基于支持向量机SVM(Support Vector Machine)机器学习的方法。基于机器学习方法,首先在已有手机行业语料库的基础上,人工标注微博文本倾向性。文本倾向性主要指利用自然语言处理和文本挖掘技术,对带有情感色彩的主观性文本进行分析、处理和抽取的过程。其次,将人工标识过的微博文本作为训练集,提取文本情感特征,通过机器学习的方法构造情感分类器。SVM是一种二类分类模型,其基本模型定义为特征空间上的间隔最大的线性分类器,其学习策略便是间隔最大化,最终可转化为一个凸二次规划问题的求解。本文运用SVM模型对是否想买手机进行分类。
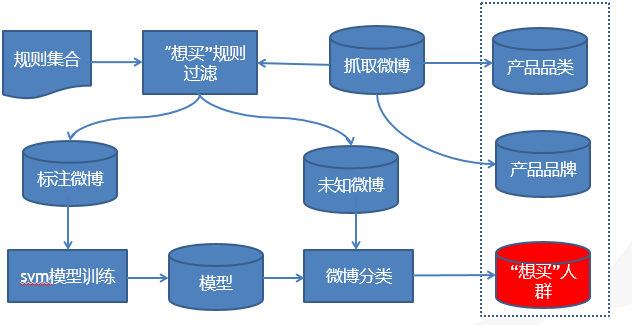
图3 微博文本分析模型分析流程
二、数据描述
(一)老用户营销列表生成模型
-
数据简介
数据源来自电商平台和线下销售公司,涵盖电视、冰箱、洗衣机、空调、手机、移动电源、空气净化器、网络机顶盒、除湿机、净水器、游戏手柄、行车记录仪等众多品类的交易行为数据。
-
数据清洗方法
数据中若干字段存在“测试人员”或“test”字样,交易频繁,疑似系统测试数据,予以删除;产品名称字段不能提供正确完整的关键词信息数据,难以识别划分到正确品类,这部分数据予以删除。以一级分类为准进入关联规则,一级赠品分类不作分析。部分品类交易量不足,难以支持定量分析,不做分析,比如游戏盒子。清洗后数据覆盖洗衣机、电视、电冰箱、手机、空气净化器、移动电源、空调、除湿机、净水机,游戏手柄、网络机顶盒、行车记录仪等12个品类。
-
变量选取确定
主要选取老用户购买人性别、联系方式、购买时间、购买品类、购买频次、购买价格等变量。
(二) 微博影响力模型
-
数据简介
数据来源新浪微博,抓取时间为2014年11月20日,品牌38个,博文数62万篇,转发数291万条,评论数296万条。
微博影响力指数评估模型所需数据为玩巴士、历趣手机应用商店、硅谷动力eNet、网易科技频道、51CTO官方微博、engadgetChina、站长之家、酷安网、RIAwind睿文网、沈阳手机网、IT茶馆、IIEEG、TomPDA、中关村在线CES2012报道官方微博、天极软件频道、搜娱网、巨细家电、IT数码家电、数码和家电、IT数码手机家电、万维家电网、环球家电、艾肯家电网、家电网、深圳家电网、电器杂志、口碑家电网、家电中国资讯网、PChome家电、家电论坛网、ZOL家电频道、慧聪家电网homea、PConline数字家电频道、中国IT杂谈、玩家电讯、IT之家、百度移动游戏、全球IT资讯、IT程序猿、199IT-互联网数据中心、IT观察猿等行业微博的50页博文内容,以及博主信息、博主的博文、博主的粉丝、博文的转发信息、博文的评论信息等。
SNA社会网络模型数据,主要通过华为荣耀6、么么哒、锤子手机、八核、4G、苹果 iPhone 6、13nubia Z7 Max、四核、安卓、IOS、Windows Phone、自拍神器、iphone、小米、三星、小米4、小米、华为、iphone 5s、小米3、三星、苹果5s、iphone5、红米Note、huawei、苹果4s、iphone4s、红米、三星S50、苹果5、诺基亚、三星 note3、5S、 华为荣耀、小米2S、 OPPO等关键词,抓取了博主信息、博主的博文、博主的粉丝、博文的转发信息、博文的评论信息等。
-
数据清洗方法
行业微博影响力指数模型,第一步从原始数据中剔除博文数少于1000,粉丝数少于10000的企业。第二步筛选出博文的转发和评论合计数前300名行业微博。第三步保障该企业博主所发布的微博内容,至少一条及以上和手机相关。将原始数据标准化,每项指数的综合值归为0-100之间。
SNA社会网络模型,数据清洗的关键点要注意剔除竞品类博主,比如小米手机创始人雷军、锤子手机创始人罗永浩、联想手机管家等,对于从微博昵称不能判断的,也要剔除,比如华为公司中国地区部消费者业务负责人,必须得进入到博主页面才能判断是否是竞品类博主。
-
变量选取确定
微博影响力指数模型,选取了各行业博主原创博文数、转发博文数、点赞数、评论数、转发数、粉丝数等六大变量。SNA社会网络模型选取了发博文人标识,回复或转发博文标识关系数据作为变量。
(三)微博文本处理模型
-
数据简介
通过华为荣耀6、锤子手机、八核、4G、苹果 iPhone 6、13nubia Z7 Max、四核、安卓、IOS、Windows Phone、自拍神器、iphone、小米、三星、小米4、小米、华为、iphone 5s、小米3、三星、苹果5s、么么哒、iphone5、红米Note、huawei、苹果4s、iphone4s、红米、三星S50、苹果5、诺基亚、三星 note3、5S、 华为荣耀、小米2S、 OPPO等关键词,抓取了博主信息、博主的博文、博主的粉丝、博文的转发信息、博文的评论信息等。
-
数据清洗方法
运用网络爬虫技术爬取相关数据,通过关键词搜索往往同一条微博内容会多次进入数据库,剔除字段都相同的数据。微博中的#话题#、URL和@用户等有些信息,不能反映用户的观点,有些为分词的噪声,对分词结果产生负面影响。本文对这类无用信息进行过滤,然后再对微博进行分词和词性标注。
-
变量选取确定
选择微博用户URL、微博的用户姓名、微博博文内容作为变量。
三、数据建模
(一)老用户营销列表模型
-
模型设定
老用户营销列表模型,在识别终端消费用户的购买频次,消费的品类,价格承受度特征基础上,通过关联规则模型,结合产品更新换代速度与实际使用寿命分类,锁定目标群体,本文重点介绍关联规则的建模过程。
基于关联规则类目购买关系分析^[赵永尊.基于品类信息的关联规则挖掘算法及其应用[D].复旦大学.2006.],采用Apriori算法,首先找出所有的频集,这些项集出现的频繁性至少和预定义的最小支持度一样。然后由频集产生强关联规则,这些规则必须满足最小支持度和最小可信度。关联规则模型几个关键指标计算公式如下:
支持度(Support):同时购买A和B的概率,
$P(A\bigcap B)$置信度(Confidence):发生购买A的情况下,购买B的概率
P(B|A)=
$\frac{A \bigcap B}{P(A)*P(B)}$提升度(Lift):使用关联组合(A B)与无规则条件下B的购买概率比
P(B|A)/ P(B)=
$\frac{A \bigcap B}{P(A)}$KULC:A,B互为条件的置信度均值,消除零事务影响
KULC=0.5*(P(B|A)+P(A|B))
KULC系数为0,表示A,B负相关,为0.5则A,B不相关;
KULC系数为1,表示A,B正相关,即A,B组合后销售量将大于A,B单独销售预期。
不平衡度(IR): 衡量A,B期望支持度的均衡关系
IR=
$\frac{|support(A)-support(B)|}{support\{A \bigcup B\}}$IR为0,表示A,B关联关系非常平衡;
IR为1,表示A,B关联关系非常不平衡,即购买A的客户很可能同时购买B,但购买B的客户却不太可能选购A。
-
模型估计过程及结果
第一步,规则初始化。选择满足最小支持度的商品项集;选择满足最小置信度的规则;选择提升度大于1的规则;
第二步,不断迭代,找出所有满足要求的关联规则;
第三步,计算KULC系数、IR不平衡度等评价指标。
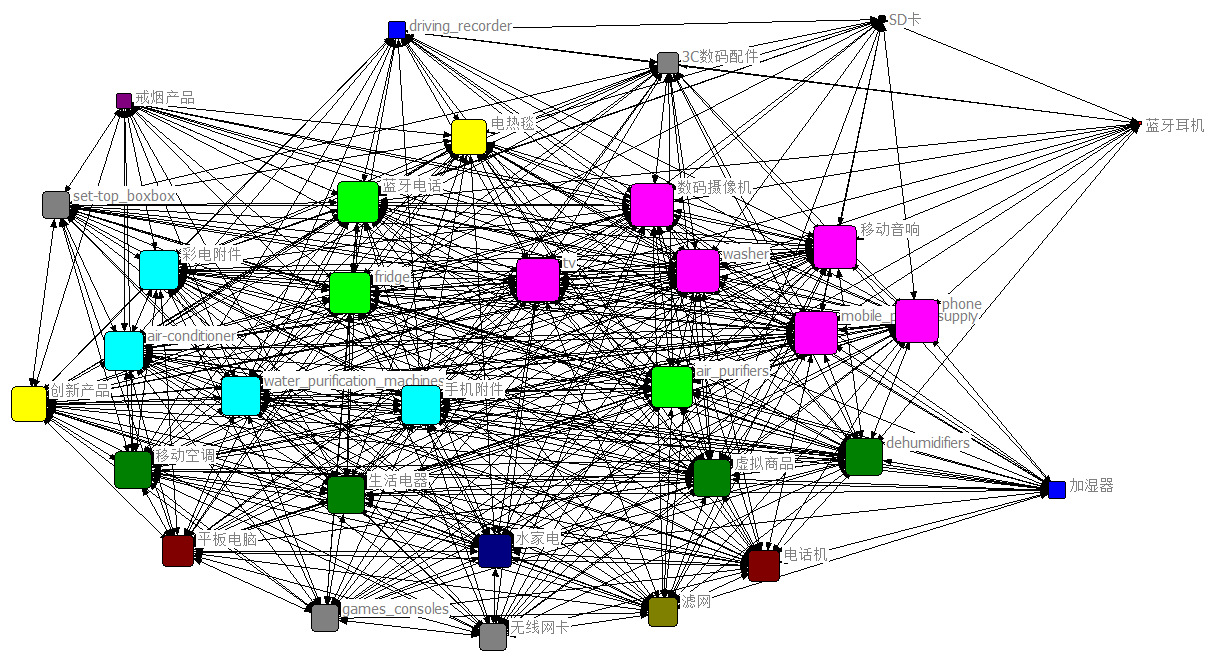
图4 品类关联网络关系图
表2 再营销名单示例
| 交易ID | 规则 | 支持度 | 置信度 | 提升度 | KULC | IR |
|---|---|---|---|---|---|---|
| X1 | {手机附件} => {手机} | 0.0639 | 0.777 | 8.868 | 0.525 | 0.602 |
| X2 | {手机附件} => {手机} | 0.0539 | 0.777 | 8.868 | 0.525 | 0.602 |
| X3 | {电视,电话机} => {手机} | 0.0493 | 0.545 | 6.222 | 0.273 | 0.999 |
| X4 | {电视,电话机} => {手机} | 0.0478 | 0.545 | 6.222 | 0.273 | 0.999 |
| X5 | {电视,电话机} => {手机} | 0.0432 | 0.545 | 6.222 | 0.273 | 0.999 |
$\ \ \ $根据关联规则-推荐价格计算方法,筛选最有可能购买新机的老用户列表。如根据新机价格,识别老用户价格承受度。已知客户A在品类X,Y的购买单价及购买数量,客户A对品类Z的推荐价格计算方法如下,以客户A为例,假设其符合关联规则{品类X,品类Y}=>{品类Z},在数据充足情况下,姑且认为各品类消费服从正态分布,估计所有品类 $\{X,Y,Z \cdots \}$ 平均消费总体分布情况。依据数据中每个消费记录对应唯一的品类,由此假设X,Y消费行为相对独立,结合客户A的购买数量 $\{N_x, N_y \}$ ,估计复合条件下{X’, Y’}消费总额分布。使用标准差评估相对位移,判断客户A在品类{X,Y}消费总额在包含购买数量关系的{X’, Y’}消费分布所处位置,较分布中心计算偏移位置 $\Delta$ ,使用品类Z的标准差,以相对位移 $\Delta$ 判断客户A在品类Z消费分布位置,可得基准推荐价格。
(二)微博影响力模型
-
模型设定
行业微博影响力指数评估模型^[付永利.网络意见领袖影响力研究[D].河南大学,2010.]基于清洗后的数据,对44个行业微博影响力进行评估。行业微博影响力指数=活跃度指数×权重1+传播力指数×权重2+覆盖度指数×权重3,其中活跃度指数等于标准化后的原创博文和转发博文乘以各自的权重;传播力指数等于标准化后的点赞数、评论数、转发数分别乘以各自的权重。活跃度指数代表您每天主动发博、转发评论的有效条数。传播力指数与微博被点赞、被转发、被评论的有效条数相关。覆盖度指数高低则取决于微博的活跃粉丝数的多少。
运用层次分析法AHP方法^[刘雁妮,贺和平,彭文莎.名人微博的影响力评价指标研究[J].武汉理工大学学报(信息与管理工程版).2012(06).]对行业微博影响力指数进行了赋权。首先邀请众多企业界手机行业专家,对指标进行两两判断,进而形成判断矩阵;其次,运用Excel软件,基于AHP方法实现了微博影响力指标权重测算过程和一致性检验过程的自动化;最后,将所得到的权重进行层层递进处理,得到了行业微博影响力指标的具体权重。
本文通过SNA社会网络模型^[赵汉青.基于SNA的微博意见领袖识别体系研究[J].电子商务.2013(09):63-64.]对微博用户进行排名,目的寻找微博意见领袖。本文主要是根据微博用户发布的微博数量,微博用户转发量和回复量的交互关系,识别入度排名最高的用户。微博用户发布的微博数量,既包括用户发布的微博数量,也包括该用户回复他人微博时发布到自己微博中的评论数量。微博转发量是指某微博用户的所有微博被转发的总量。微博回复量是指针对该用户微博的全部评论的总量。
-
模型估计过程及结果
层次分析法(AHP)的具体运算可以分为三个步骤。
构造判断矩阵
假设针对上一层设置目标
$C_k$,需要评判元素$D_1,\cdots,D_n$的重要程度,则首先构造元素$D_1,D_2,\cdots,D_n$的两两判断矩阵T。该判断矩阵表示针对上一层次指标$C_k$而言,该层次中各有关元素$D_1,\cdots,D_n$的相对重要性。其中$d_{ij}$表示对于上一层目标$C_k$而言,元素$D_i$对$D_j$的相对重要性。其形式如表3所示。
表3 判断矩阵B的形式
| 针对上一层 | 因素 | ||||
|---|---|---|---|---|---|
| 目标Ck | |||||
| D1 | D2 | … | Dn | ||
| D1 | d11 | d12 | … | d1n | |
| 因素 | D2 | d21 | d22 | … | d2n |
| … | … | … | … | … | |
| Dn | d1n | dn2 | … | dnn |
计算重要性排序
本文采用和积法方法求解判断矩阵B的最大特征根及对应的特征向量,所求特征向量即为各评价元素的重要性排序,归一化后即是权数分配。由于判断矩阵本身是将定性问题定量化的结果,允许存在一定的误差范围,所以常常用近似算法求解判断矩阵的最大特征根及对应的特征向量,如和积法、方根法和幂方法等。
一致性检验
一是计算一致性指标CI(Consisteney Index)
$CI=\frac{1}{n-1}(\lambda_{max}-n)$
其中$\lambda_{max}$ 为最大特征根,n 为判断矩阵阶数。
当判断矩阵具有完全一致性时,CI=0;越大,矩阵的一致性就越差。为了检验判断矩阵是否具有满意的一致性,需要将CI与平均一致性指标RI(Random Index)进行比较。
二是查找相应的平均随机一致性指标RI
表4 平均随机一致性指标RI
| n | RI | n | RI | n | RI |
|---|---|---|---|---|---|
| 1 | 0 | 6 | 1.24 | 11 | 1.52 |
| 2 | 0 | 7 | 1.32 | 12 | 1.54 |
| 3 | 0.58 | 8 | 1.41 | 13 | 1.56 |
| 4 | 0.9 | 9 | 1.45 | 14 | 1.58 |
| 5 | 1.12 | 10 | 1.49 | 15 | 1.59 |
三是计算一致性比例CR
$CR=\frac{CI}{RI}$
当 CR < 0.1 时,即认为判断矩阵具有满意的一致性,说明权数分配是合理的;否则,需要修正判断矩阵,直到取得满意的一致性为止。
本文运用AHP方法对行业微博影响力指数指标进行了赋权。首先邀请业界众多专家,对指标进行两两判断,进而形成判断矩阵^[丁雪峰,胡勇,赵文,吴荣军,胡朝浪,杨勇.网络舆论意见领袖特征研究[J].四川大学学报(工程科学版). 2010, 42(02):145-149.];其次,运用Excel软件,基于AHP方法实现了指标权重测算过程和一致性检验过程的自动化;最后,将所得到的权重进行层层递进处理,得到了指标的具体权重,且通过了一致性检查,在此基础上综合加权计算综合影响力指数。最具话语权的行业微博为百度移动游戏、万维家电网、家电网。
表5 44个行业媒体微博影响力指数及各分项指数排名
| 影响力指数 | 活跃度指数 | 传播力指数 | 覆盖度指数 | |||||
|---|---|---|---|---|---|---|---|---|
| 得分 | 排名 | 得分 | 排名 | 得分 | 排名 | 得分 | 排名 | |
| 百度移动游戏 | 89.1 | 1 | 79.0 | 5 | 88.2 | 1 | 100.0 | 1 |
| 万维家电网 | 74.5 | 2 | 76.5 | 10 | 70.7 | 3 | 76.2 | 3 |
| 家电网 | 70.7 | 3 | 79.2 | 4 | 41.1 | 21 | 91.7 | 2 |
| engadgetChina | 68.7 | 4 | 71.5 | 15 | 63.6 | 4 | 71.0 | 4 |
| 199IT-互联网数据中心 | 63.1 | 5 | 15.0 | 12 | 50.4 | 7 | 63.9 | 5 |
| 站长之家 | 60.1 | 6 | 82.8 | 1 | 48.3 | 8 | 49.2 | 6 |
| IT茶馆 | 57.5 | 7 | 80.5 | 3 | 44.5 | 12 | 47.5 | 9 |
| 慧聪家电网homea | 57.4 | 8 | 74.9 | 13 | 52.1 | 6 | 45.3 | 13 |
| 网易科技频道 | 56.5 | 9 | 76.9 | 8 | 46.2 | 9 | 46.5 | 10 |
| 环球家电 | 56.2 | 10 | 82.3 | 2 | 42.2 | 17 | 44.1 | 15 |
| 51CTO官方微博 | 55.7 | 11 | 78.9 | 6 | 42.1 | 18 | 46.2 | 11 |
| 硅谷动力eNet | 55.5 | 12 | 76.9 | 9 | 45.2 | 11 | 44.3 | 14 |
| PChome家电 | 55.3 | 13 | 60.3 | 20 | 57.1 | 5 | 48.7 | 8 |
| 艾肯家电网 | 53.6 | 14 | 71.2 | 16 | 40.4 | 24 | 49.1 | 7 |
| 沈阳手机网 | 53.6 | 15 | 78.6 | 7 | 40.0 | 33 | 42.1 | 17 |
入度^[刘军.整体网分析讲义UCINET软件实用指南[M].格致出版社.2009.]即为以某顶点为弧头,终止于该顶点的弧的数目称为该顶点的入度,$D(i)=\frac{1}{n-1}\sum_{i=1}^na_{ij}$ ,$a_{ij}$ 表示所有点j到点i的入度,和i有关系值为1,否则为0.当某微博主发博时,被很多人转发或者评论,符合入度特征,我们认为网络入度是对影响力的重要度量指标。点的中间中心度测量的是该点在多大程度上控制他人之间的交往。如果一个点的中间中心度为0,意味着该点不能控制任何行动者,处于网络的边缘,如果一个点的中间中心度为1,意味着该点可以100%地控制其他行动者,它处于行动者的核心,拥有很大的权力。点i的绝对中间中心度记为CABi= $\sum_j^n\sum_k^nb_{jk}(i)$ , $j \neq k \neq i$ 并且 $j<k$ 。点i的相对中心度CRBi= $\frac{2C_{ABi}}{n^2-3n+2}$ 。由于中间中心度和网络入度对影响力都是正力,因此我们可以假定:I(i)=aC(i) + bD(i).C(i)是绝对中间中心度,D(i)是网络入度,基于此,我们建立一个逻辑回归模型,通过博主的粉丝数及在行业的影响力我们定义网络中的训练样本和测试样本中的是否为意见领袖^[刘军.整体网分析讲义UCINET软件实用指南[M].格致出版社.2009.]。通过交叉验证获得最后的分析模型,获得a和b的估计值,最后用此模型进行预测找到网络中的意见领袖,下图中大的圆圈即是计算出的意见领袖。

图5 SNA社会网络图
(三)微博文本处理模型
-
模型设定
通过SVM分类方法^[韩忠明,张玉沙,张慧,万月亮,黄今慧.有效的中文微博短文本倾向性分类算法[J].计算机应用与软件. 2012(10): 89-93.],基于新浪微博数据进行特征提取及权重计算,进而判断情感倾向分类。首先采用百分点中文语义分析平台工具对微博进行分词,然后选择了词性、情感词、否定词、程度副词及特殊符号等抽取文中的特征,并运用SVM模型进行训练。为了找出最优特征组合,评估每种特征对SVM模型作用的大小,本文将词性和情感词特征组合后,分别加入否定词、程度副词和特殊符号特征。通过多组特征不同组合的反复试验训练,找到最佳特征组合^[何凤英.基于语义理解的中文博文倾向性分析[J].计算机应用.2011,31(08):2130-2133.]。
从样本数据中提取特征,首先对样本数据进行预处理、分词和词性标注。对每条样本数据进行过滤处理,只留下名词、动词、形容词。
计算每个词w的包含、不包含正负情感的文本个数(A、B、C、D)
A:包含w并且所在样本数据正面情感的文本数量
B:包含w并且所在样本数据负面情感的文本数量
C:不包含w并且所在样本数据正面情感的文本数量
D:不包含w并且所在样本数据负面情感的文本数量
对每个词w计算
$X^2$估计(CHI)$X^2$计算的是特征w与类别C之间的依赖关系。如果w与C之间相互独立,那么文本特征w的估计值为零。对于类别C,文本w的$X^2$ 估计定义为:$$x^2=\frac{N \times (A \times D – C \times B)^2}{(A+C) \times (B+D) \times (A+B) \times (C+D)}$$对样本和测试数据基于特征词进行向量化处理。统计每个特征项在该文本数据中的个数m(TF),基于TF×IDF=m×lg
$\frac{N}{A+B}$,计算各个w的权重值,将样本及测试数据向量化存储^[王素格,杨安娜,李德玉,魏英杰,李伟,张武.基于支持向量机的文本倾向性分类研究[J].中北大学学报(自然科学版).2008, 29(05): 421-425.]。本文基于机器学习的情感分类算法中,每篇博文转换成一个对应的特征向量来表示,分类器参数采用默认值。实验结果采用准确率、召回率和综合分类率来作为评价标准^[吴维,肖诗斌.基于多特征与复合分类法的中文微博情感分析[J].北京信息科技大学学报(自然科学版). 2013(04):39-45.]。
-
模型估计过程及结果
支持向量机的准确率达到80%以上,输出结果,微博用户的url,微博用户名字,品牌,以及该用户想买可能性的得分。
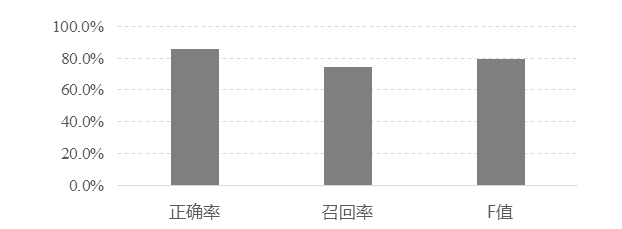
图6 情感倾向性判别结果
表6 可能购买新机名单示例
微博用户名称 品牌 URL 微博内容 X1 TCL http://weibo.com/u/3847650691 我也想买么么哒! X2 华为 http://weibo.com/u/1885694024 我一定要帮老爸抢到华为荣耀3c,话说现在买个手机真的好累。限时限量,还得预约,还比网速 X3 HTC http://weibo.com/u/1948085310 心动了,好想买 X4 华为 http://weibo.com/charlie0702 想买华为mate7!自从去年P6发布就从路人转粉了
四、业务实施
(一)老用户营销列表业务实施
在老用户营销中,我们经过建模加权之后的结果,找到不同等级的目标,用户群体超过10万人。通过筛选之后进行营销活动信息短期的推送,效果比盲投广告提升了3倍。
(二)微博影响力模型业务实施
一是通过与具有话语权的行业微博合作,树立行业高度,行业意见领袖评论稿件侧重宣传新机的社交亲密功能,凸显该产品的优势,提升了行业高度与产品权威。二是通过与个人意见领袖合作,引领新机话题等等,使得覆盖的粉丝群体了解品牌与产品,从而为新机预约吸引了很多关注,产品好感度明显提升。
据统计,新浪微博新机话题阅读量已达4.6亿,讨论量近30万;新机活动更是达到了7.2亿的阅读量和30.4万的讨论量;期间新机多次登上热门搜索和热门话题榜。话题量和搜索量飙升,新机百度指数峰值近15万,网页收录量360多万。
(三)微博文本处理模型业务实施
运营人员根据文本处理模型得到的微博ID号和链接地址,发私信给想买手机的用户,并与这些用户紧密互动沟通,满足用户的心理诉求,提升用户消费体验。这批用户最终预约购买率高达85%以上,有效地提高了销量。
五、总结讨论
(一)老用户营销列表生成模型局限性及改进方向
老用户营销通过用户购买品类行为的关联规则模型,挖掘顾客购买的商品之间各种联系,发现用户的潜在需求,促进产品的交叉销售和向上销售。本文并未考虑老用户的性别、年龄、地域、消费等级等属性标签,与品类购买之间的多维关联性。未来将会引入改进的多维关联规则算法^[张同启.基于关联规则和用户喜好程度的综合电子商务推荐系统的研究[D].北京邮电大学.2015.],综合考虑用户性别、年龄、地域、消费等级,以及产品的各种参数特性,从大量数据中进一步挖掘数据间的关联关系,以便提高营销的精准度。
(二)微博影响力模型局限性及改进方向
微博影响力模型所需要的原创博文数、转发博文数、点赞数、评论数、转发数、粉丝数等六大变量数据,来自最近50页博文相关的累计数据,不能体现最近一段时间的行业微博影响力和个人微博影响力的动态变化趋势。未来要考察在特定时间范围内对微博影响力进行评估,比如粉丝数仅为评估时期内新增的粉丝数,而不是累计粉丝数等等。
(三) 微博文本处理模型局限性及改进方向
本文采用支持向量机SVM方法,准确率和召回率都较高,且具有较好的稳定性。在统计样本相对较低的情况下,也可以得到很好的学习效果。但是这类方法具有一定的局限性,对语料库高度依赖。微博语言复杂多变,往往一个行业语料库的积累需要很长时间,且需要动态积累、丰富、完善。未来要丰富该行业的语料库,从语料的收集、预处理、标注规范的制定、质量监控等方面都需要不断完善和提升。
敬告各位友媒,如需转载,请与统计之都小编联系(直接留言或发至邮箱:editor@cos.name),获准转载的请在显著位置注明作者和出处(转载自:统计之都),并在文章结尾处附上统计之都微信二维码。

发表/查看评论