作者:
- 陈星(中央财经大学统计与数学学院,北京)
- 潘蕊(中央财经大学统计与数学学院,北京)
- 黄亮(彩虹无线(北京)新技术有限公司,北京)
摘要:本文的研究内容为UBI车险业务。本文通过车辆前装设备采集驾驶行为数据,并与同期车辆出险情况建立Logistic回归模型,通过该模型挖掘对车辆出险情况具有显著影响的驾驶行为变量,并对其影响程度进行分析。根据分析结果,本文对其在行程打分与车险保费定价两部分业务的实施进行了分析,并对其预期效果与可能存在的问题展开了进一步讨论。
关键词:车联网大数据;驾驶行为;Logistic 回归模型;UBI车险
一、业务介绍
(一)车联网行业介绍
车联网(Internet of Vehicles)是指由车辆位置、速度和路线等信息构成的巨大交互网络。车联网主要依托移动通信与信息科学技术,通过无线通信技术(例如 GSM, GPRS等通信方式)、地理位置定位技术(例如 GPS,LBS定位)、汽车传感器技术(汽车总线 CAN-bus) 以及行车记录仪技术等完成车辆行驶状态与周边环境的采集、数据的传输与处理工作^[郁佳敏. 车联网大数据时代汽车保险业的机遇和挑战[J]. 保险研究, 2013(12), 89–95.]。车联网行业目前处于飞速发展阶段。根据中国产业信息网的车联网行业分析报告,车联网用户数在2005年至2013年由5万增至600万,且将随着我国汽车保有量的增加而进一步增长,其市场规模将从130亿元增长到665亿元,并将保持30%到50%之间的高速连续增长。
车联网的发展为其行业创造了海量数据,而该行业的主要价值也将基于其数据的信息价值体现。其可以收集车与人、车与车、车与路的属性信息和静、动态信息,从而形成一个极为庞大的数据库,为使用车联网的行业提供其所需要的数据信息^[韩成卉, 赵绰翔, 郑苏晋. “行为定价保险”:车险定价与驾驶行为理论[J]. 金融发展研究, 2015(8), 68–74.]。车联网数据可应用于广告投放、智能交通、车辆维修保养以及车辆保险等多个领域。在广告投放方面,可通过车联网数据在云端的整合,发现司机青睐的车辆维修网店,加油站等,从而能够有针对性的对用户实现广告的精准投放;在智能交通方面,其可通过分析预测交通状况,预警交通拥堵路段,及时协助交通管理部门发现问题并制定相应的交通分流、疏导方案;在车辆维修保养方面,基于车联网设备提供的各项车辆实时指标情况,从而帮助车主发现车况问题,并为车辆维修保养机构提供问题原因以及解决方案。
(二)车险行业介绍
随着道路交通行业的持续发展,我国民用汽车保有量呈现逐年快速增长的趋势,近10年年增长率均超过15%。截止至2015年底,我国民用汽车保有量已达到16273万辆,具体情况如图1所示^[数据来源:国家统计局]。汽车行业的繁荣为车险行业提供了蓬勃发展的平台,从而使得车险产品具有广阔的发展空间。传统的车险已经成为我国财产保险业务的第一大险种,其主要产品由中国人保,太平洋保险和中国平安三家保险公司提供。传统车险产品主要通过从车因素、从人因素、从环境因素三个方面衡量被保险人的风险水平,从而确定其保费。其中从车因素指车辆种类、型号、用途、车龄、行驶区域以及生产厂商等因素;从人因素指驾驶人年龄、性别、驾龄、婚姻状况、职业以及肇事记录等因素;从环境因素指气候、地貌、路况等地理环境风险因素以及治安、法制情况等社会环境风险因素。尽管传统车险产品考虑因素众多,但在竞争日益激烈的市场环境下,仍存在产品单一、费率条款粗放以及准备金低估等问题[1],这类问题反映出车险产品对风险把控的不足。因此仅根据上述三方面因素确定保费将低估风险,从而导致保费无法与风险合理匹配,造成车险行业经营效率低下。
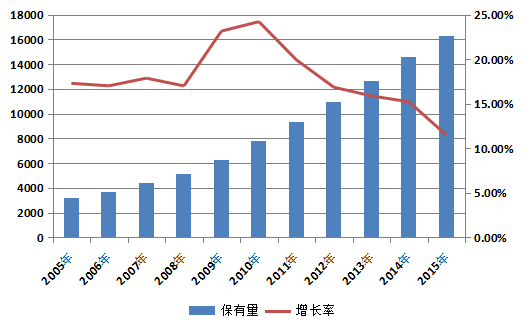
图1中国民用汽车保有量与年增长率时间序列图
除了上述因素之外,司机的驾驶行为也是衡量风险的重要因素,对车险保费定价有指导作用。然而传统车险行业未通过司机驾驶行为进行保费定价,其主要原因有以下几方面:①缺乏驾驶行为的数据支持;②缺乏相应的数据处理技术;③缺乏相应的政策支持。目前,随着移动通讯行业的发展,车联网大数据已可实现实时采集,为基于司机驾驶行为的分析提供了数据支持;随着软硬件技术的发展,该类车联网数据可通过分布式集群、云计算等方法进行建模分析,并通过其与传统保险精算方法的结合实现保费的定价,从而解决了数据处理问题;同时,保险大数据公司的诞生与车险费率改革制度的出台也推动着新的车险定价模式的诞生。这种新型车险就是UBI(Usage Based Insurance),即基于驾驶人行为的车险。
(三)UBI业务背景
1、业务定义
UBI模式车险是基于驾驶行为以及使用车辆相关数据相结合的个性化保险产品。保险公司通过与车厂合作,通过远程信息处理技术获取车辆行驶信息,并将其上传到公司服务器。该类信息包括车辆行驶过程中的里程、油耗、时速等数据,保险公司结合时间、路况与车辆状况,计算得出司机各类驾驶行为的发生情况,通过大数据处理与分析技术评估车主驾车行为的风险等级,通过风险等级指数为其提供个性化保单,从而实现风险与保费定价的匹配。UBI模式车险作为大数据时代的新型车险,其具备科技与方法二者的创新。UBI的核心概念在于给予具有安全驾驶行为的司机保费优惠,其推广不仅能够使保险公司强化车险定价能力,还可以产生良好的个人与社会效应,引导司机形成良好的驾驶习惯。
2、业务发展现状
UBI模式车险业务在国际上的发展已经较为成熟。在美国保险市场,UBI业务代表公司为progressive保险公司,该公司于1994年首度提出PAYD(pay as you drive)保险概念^[韩雪, 赵绰翔, 郑苏晋. 车联网保险商业模式及案例分析[J]. 上海保险, 2015(11), 50–54.],之后又陆续推出autograph、tripsense等几代UBI产品,并于2009年正式推出引入驾驶员急刹车次数、夜间行车次数等数据的UBI保险产品Snapshot。美国State Farm保险公司其后推出In-Drive保险产品,该产品根据司机驾驶行为提供了高达50%的车险费率折扣。在欧洲保险市场,英国保险合作社Cooperative Insurance Society、Insure The Box保险公司,德国、荷兰、意大利等国保险公司先后推出各类基于驾驶行为折扣保费的UBI保险产品。在亚洲保险市场,日本爱和谊日生同和保险公司于2005年与丰田合作在日本推出了类似UBI的车险产品PAYD,该产品仅针对累计里程折扣保费,而未加入其它驾驶行为数据。
国内的UBI模式车险业务尚处于市场探索阶段,但其已具备推出基础:保险大数据公司的成立与车险费率改革制度的发布为中国UBI车险业务提供了政策支持,大数据、云计算、车联网技术的成熟为该业务提供了技术支持,前装与后装市场以及智能APP的出现则为该业务提供了丰富的数据基础,从而为中国UBI业务的启动创造了空间。
3、业务目标
UBI业务的相关群体主要为保险公司与投保人。对于保险公司,其短期业务目标为领先推出UBI产品,抢占客户资源。其长期业务目标为通过客户反馈,深入了解客户需求,不断更新与改进车险产品,建立更完整的产品体系,在留住老客户的基础上不断吸引新客户,从而获得更大市场份额。对于投保人,UBI业务将实时向投保人反馈各段行程中驾驶行为以及保费变动情况,帮助投保人了解其行车过程中存在的不安全驾驶行为,并通过保费激励投保人改善其驾驶行为,从而减少交通事故发生频率。
(四)研究方法
本文将通过车载前装设备采集行车数据,根据该数据计算每辆车全年各类驾驶行为变量,并根据司机在数据采集周期内出险情况与驾驶行为变量建立广义线性模型。通过变量选择获取对车辆出险有显著影响的驾驶行为,并得到驾驶行为变量对出险概率的影响程度。该模型可协助保险公司发掘影响车辆出险的重要行为,从而对司机保费进行差异化定价^[彭江琴, 刘南杰, 赵海涛,等. 智能UBI系统研究[J]. 计算机技术与发展, 2016(1), 142–146.]。
二、数据描述
(一)数据来源
驾驶行为数据指车辆运行过程中描述车辆行驶状况的数据,该类数据在车辆运行过程中实时采集。该类数据的采集方式有三种,①前装,即在汽车出厂前已将数据采集设备作为车辆的一部分安装在车上;②后装,即通过OBD(车载自诊断系统)设备,通过车上配有的终端接口在车辆使用过程中自行安装;③手机APP,即通过手机软件对数据进行采集。以上三种数据采集发生各有利弊:前装设备的优势在于其使得厂商配套生产相对容易,从而更能够保证数据的完整性。但其进入门槛相对较高,需要与各类车辆车厂达成合作关系方可获取,且由于其设备作为车辆的一部分,安装后将难以取下。后装OBD设备具有进入门槛低,生产成本低等优势。但其存在说服成本较大,不同品牌终端竞争激烈,同时存在一定安全隐患,这将使得用户在安装后可能更换品牌或放弃使用,导致数据收集难以持续进行,对后续的数据分析和挖掘来说有很大限制。而手机APP则具有安装容易,产品更新方便等优势。然而其存在数据精度较低、且客户更换产品成本较低导致客户容易流失等问题。
本文采用的数据为前装数据,通过对接车内传感器及车机,在车辆运行过程中获取车辆状况与行驶状况。每个车辆在驾驶过程中,以秒为采集频率生成一条记录,每条记录包含车辆信息、时间信息、车况信息、驾驶信息以及地理位置信息等多种类型的数据。出险情况数据指观测车辆在驾驶行为观测周期内是否发生交通事故并向保险公司申请保险索赔的数据。该批出险情况数据包含车辆标示VIN码与是否出险两个变量,将用于对司机驾驶风险进行评估。
(二)数据概述
原始数据为两千余辆已识别是否出险的车辆于2014年7月至2015年6月共计12个月产生的数据。数据共包含8个变量,囊括四类信息,①标识信息,包括车架号(VIN),为车辆的唯一标识编号。②时间信息,包括数据上传时间,代表数据由车辆上传到数据库的时间。③位置信息,包括经度与纬度,可反映车辆实时所处位置,本文在目前的研究中尚未使用该数据。④行驶信息,包括累积里程,瞬时油耗,瞬时车速与瞬时发动机转速。各个变量的具体情况见表1。

(三)建模变量
在生成建模所需要的变量前,本文首先对车辆行程进行划分。本文通过车辆行驶过程中较长时间的熄火状态将车辆的运行划分为多段路,其中每段路称为一个行程。本文基于以行程为单位的变量计算得到建模所用的车辆变量数据,下文将对该类建模变量的选择进行详细说明。
本文基于原始变量计算得到10个建模变量,其中包括累计值类变量,平均值类变量,标准差类变量,极值类变量与比例类变量。①累计值变量为年化累计里程,它反映出一辆车一整年行驶的里程数,该变量在UBI模型中为一个重要变量。②平均值类变量包括日均行程数、平均时速、平均油耗与平均发动机转速。平均值类变量反映出司机驾驶行为整体上的集中趋势。日均行程数代表一辆车平均每天行驶的行程个数,其通过一辆车一年的行程总数与其出行天数相除所得。平均时速表示车辆一年行驶的平均速度,其衡量了司机在整体上的行驶速度。平均油耗与平均发动机转速则是对其的侧面补充。③标准差类变量包括时速的标准差,其反映了司机驾驶时速的变化程度,能够体现司机驾驶的平稳性。④极值类变量包括最大时速,为司机全年行驶时速的最大值,反映了司机时速的极端情况。⑤比例类变量包括早、晚高峰与夜间出行的占比,该类变量反映了司机是否经常在非常时间段出行,该类时间的出行将对车辆出险有较强影响。本文下文的描述性分析与数据建模均基于本部分得到的建模变量。
三、数据建模
(一)描述性分析
本文进行建模分析的数据包含10个数值型自变量,1个0-1型因变量。我们对10个数值型自变量进行了简单的描述性分析^[由于数据保密性需要,不展示描述分析具体数值细节]。
在累计值类变量方面:从年化累积里程变量可看出,平均每位司机一年行车约1万4千公里,平均每日约行驶40公里。多数车辆一年内累计里程在2万公里以内,这类车辆可能主要用于代步,行驶范围相对集中。少数车辆一年行驶里程非常长,可能存在长途或疲劳驾驶等情况。针对这类车辆,其出险概率可能将有所上升。年化累积里程在不同司机间存在较大差距,在PAYD等车险模式中其为对车险保费定价具有重要影响的变量,故本文在建模分析中将更加关注该变量对出险情况的影响。一般而言,驾驶更多里程的司机有更大可能出险。
在平均值类变量方面:司机平均一年的驾驶速度不到25公里/小时,这在城市中为一个相对较慢的速度,但考虑到车辆起步、等待红绿灯以及拥堵等怠速行驶情况,该速度相对合理。平均时速最小的车辆时速不到12公里/小时,其长期处于极度拥堵状态。
在极值类和比例类变量方面:平均最高时速超过120公里/小时,已超过最高限速,说明有较多司机存在有较大安全隐患的超速行驶行为。司机处在高峰期的时间约占三分之一,其中司机更多在晚高峰出行。高峰出行最多的司机一年中超过一半的时间处在高峰期,而最少的基本不在高峰出行,说明司机在出行时间的选择上存在差异。平均而言,司机仅有2%的时间在夜间出行。
(二)模型设定
由于因变量为0-1型分类变量,本文应采用分类方法对数据进行建模预测。常用的分类方法有Logistic回归,决策树,随机森林,神经网络等。本文采用Logistic回归对数据进行建模分析,其原因有以下几点:①Logistic回归能通过回归方程展现因变量与自变量关系。本文建立模型的目标是为UBI车险提供定价基础,其需要挖掘对车辆出险情况有显著影响的驾驶行为并得到其影响程度。因此,本文需要得到能够反映各个自变量对因变量影响程度的模型,在上述分类模型中,仅Logistic回归能够满足要求。②Logistic回归能够进行变量选择。其它几类模型通过全部自变量对因变量空间进行划分,因而无法剔除对因变量影响程度较小的自变量,而Logistic回归则能在全变量基础上通过AIC信息准则进行变量选择,得到对因变量有显著影响的自变量。③Logistic回归计算量较小,运算速度较快。由于随机森林、神经网络等算法涉及多次迭代,其运算成本较高,而Logistic回归运算相对较快,在未来车辆进一步增多,数据量加大的情况下将降低运算成本。
本文采用Logistic回归进行建模,模型如下所示:
$$P(Y=1|x)=1/(1+e^{-g(x)})$$
其中,$g(x)=\beta_0+\beta_1x_1+\beta_2x_2 + \cdots +\beta_{10}x_{10}$。本文通过极大似然估计对$\beta$参数进行求解,之后通过似然比检验对参数显著性进行检验。求解后,本文通过AIC信息准则进行变量选择,得到本文最终的UBI车险模型。
本文在建模前首先对数据进行标准化处理。由于自变量量纲不同,不同自变量间数值差距较大,为使得自变量直接具有可比性,本文对全部自变量进行对数变换,之后对其进行标准化。
(三)模型结果
Logistic回归通过AIC进行变量选择后的变量回归系数符号与显著性水平如表2所示,变量影响程度如图5所示^[显著性水平为0.1]。根据表2结果,在累计值类变量中,年化累积里程对出险情况有显著影响,其参数估计结果为正,说明随着里程数量的增加,车辆有更大可能出险,这与PAYD车险的规律相同。在UBI模型中,累计里程同样是衡量保费定价的重要标准,因此针对开车更多的司机,应相对多收取保费,而对行驶较少甚至不开车的司机,应给予其保费优惠。在均值类变量方面,日均行程数与平均时速变量皆显著。日均行程数变量回归系数为负,这说明,在给定相同的行驶里程的条件下,每天出行次数越多的司机,出险概率越低。平均时速变量同样回归系数为负,说明行车速度越快的司机越不易出险,其可能原因有两点,第一,驾驶技术较熟练的司机可能对路况把控更到位,因此能够以相对较快的速度行驶且保证行车安全。第二,在相对拥堵导致时速较慢的路段行车比在正常运行的路段更容易发生交通事故。根据图2所示结果,在变量影响程度方面,年化累积里程变量对车辆出险情况影响最大,其次为日均行程数,之后为平均时速。
四、业务实施
(一)实施方案
本文在获得基于驾驶行为预测车辆出险情况的模型后,根据模型结果对两部分业务的实施进行了分析,第一部分为分段行程打分业务;第二部分为UBI车险保费定价业务。
行程打分的目的是向司机提供一个完整的驾驶行为反馈系统,在司机结束一段行程后,对其驾驶情况进行合理评价,对其潜在的高风险驾驶行为进行提醒,从而引导司机改善不良驾驶习惯。本文将在模型基础上计算每段行程得分,具体可分为以下几步:①建立分数与出险概率的映射关系。由于出险概率取值范围为0到1,而行程得分取值范围为0到100,因此应对模型进行线性变化,使因变量取值范围由1到0映射到0到100之间。②建立重点指标反馈体系。本文将建立易于解释且更为关键的重点指标体系,有针对性的对司机反馈其行车过程中的高风险驾驶行为。③建立得分排行榜与用户交流平台。目前许多行车软件均已有相应的行程评价,本文认为应在其基础上将其与社交圈相结合,在每天结束时向司机反馈当天驾驶得分,并构建安全驾驶排行榜,利用司机的好奇心理与比较心理促进其规范驾驶行为,安全行车。同时,该用户交流平台将给司机带来较强的参与感,使客户接触增加,从而增强了公司的客户粘性。
UBI车险保费业务为本文要讨论的重点业务,本文建模分析的主要目标即为该部分提供数据分析支持。UBI车险业务的目标为建立一种全新的基于驾驶习惯与行驶里程对保费定价的车险产品,从而实现对客户的细分,提升保险公司的风险区分能力^[朱仁栋. 车联网保险与商业车险改革[J]. 中国金融, 2015(8), 63–64.]。UBI车险模型能帮助保险公司根据司机驾驶行为识别其风险等级,对高风险司机将通过保费惩罚给予其经济激励,使其减少不良驾驶行为;对低风险司机将为其提供更具有吸引力的价格与服务。通过对风险的合理掌控,保险公司将降低赔付成本,从而使得公司盈利空间上升。UBI车险保费的定价将参照本文建模结果,并根据保险精算方法制定合理的保费优惠与惩罚策略。本文认为保费应实时浮动,而浮动的范围则分为几档,分别对应不同的行程得分。在每段行程结束后,基于上述模型结果对该段行程打分,如果行程得分较高,则对司机给予保费奖励,反之,若该段行程出现较多高风险驾驶行为,导致得分较低,则应对司机给予保费惩罚。在UBI车险进入市场初期,本文认为保险公司需采取低价策略增强新产品的吸引力^[王辉. 众安保险进军车险市场,探索“互联网+车险”商业模式[J]. 中国保险, 2015(11), 2–2. ],提高保险公司知名度,迅速开拓市场,争取占得较大市场份额;在市场发展期,保险公司应在客户群基础上,对保费水平进行调整,逐渐由扩展型战略转向盈利型战略,同时,根据用户反馈对产品功能进行改进,从而获得稳定的客户群体;在市场成熟期,保险公司应已具备一定用户量,之后可通过产品口碑,通过老用户吸引新用户加入,在保持盈利的基础上进一步扩大客户群体。
(二)预期效果
根据行程打分业务需要公司对司机的驾驶行为进行评价与反馈。该部分的实施首先可以帮助司机发现行驶中的高风险驾驶行为,在发现的基础上,利用司机的比较心理,通过得分与评比督促司机反思与改善其驾驶行为,从而获取更高得分。随着该评分体系的普及,将有更多司机加入其中,从而相互促进谨慎行车,在整体上减少社会交通事故的发生。
与行程打分业务相比,UBI车险保费定价业务将成为一个盈利性核心业务,本文对该类车险进入市场后在产品发展、保险公司经营与投保人使用的预期效果进行了分析。在产品发展方面,保险公司通过用户的反馈不断对保费定价做出调整,从探索阶段逐步走向成熟,从以吸引用户的低价车险逐步发展为通过市场决定的均衡价格;在保险公司经营方面,公司从通过融资进行保险市场扩张,逐渐提高用户粘性与满意度,从而逐步转型为通过UBI车险盈利,并在此基础上不断改进产品,从而获取更大市场份额;在投保人使用方面,投保人通过该类车险的经济激励规范驾驶行为,安全驾驶[2],随着投保人数量的增多,该车险将培养个体的优秀驾驶行为,从而促进社会交通向安全驾驶方向发展,创造更加良好的社会交通环境。
(三)可能存在的问题与解决方案
目前行程打分业务存在的问题有以下两点:①过低分数引发用户不满。当司机在行程中存在较多高风险驾驶行为时,其行程分数可能过低,引发司机的不满情绪。针对该种情况,本文认为设置用户可接受的最低得分,从而减少因为对得分不满而造成的用户流失。②司机对行程得分与驾驶行为反馈产生质疑。针对该类问题,本文建议对产品建立完善的反馈体系,可以令司机通过简单操作将其质疑的问题反馈给公司,而公司则建立健全的客户服务部门及时回应司机的疑问。
目前UBI车险保费定价业务可能存在以下几点问题:①投保人对保费惩罚产生质疑。该问题与打分业务的问题②相似,针对该问题,应建立合理的反馈体系,在弥补投保人损失的前提下,给予其补偿性优惠。②车险保费盈亏不均衡,导致保险公司亏损。针对该类问题,应在UBI模型基础上调节对各类驾驶行为的惩罚力度。在运营时,首先通过一段时间的试运营,让投保人熟悉该类车险,并使公司根据试运营效果调整车险保费模型,从而使得保费合理定价。③随着UBI车险的出台,司机驾驶行为发生改变,导致现有模型不再适用。在该UBI车险正式出台后,阶段性的对模型盈利情况重新评估,调整模型,在保证投保人利益的情况下合理制定保费收取情况。
五、总结与讨论
本文重点工作为通过驾驶行为数据建立UBI车险模型,挖掘造成车辆出险的不安全驾驶行为以及其对出险概率的影响程度。根据模型结果,本文得到3个对车辆出险概率有显著影响的变量,其中导致车辆出险概率上升的变量有年化累计里程比;导致车辆出险概率下降的变量有日均行程数,平均时速。本文在模型基础上探讨了其在行程打分与UBI车险保费定价业务上的实施,其中模型在行程打分业务上已有较好的表现,而其在UBI车险保费定价业务上尚未实施,本文对其预期效果与实施过程中可能存在的问题进行了进一步讨论。
本文认为目前文章可供改进的方面有以下几点:①数据的改进。目前数据采用的是司机一整年的驾驶行为数据以及相同时间段的出险情况,该数据有以下几点问题,第一,无法确定车辆出险发生的具体时间,这将导致未引发车险的驾驶行为被错误评估,而实际造成出险的行为被低估;第二,无法保证车主的连续性,由于同一辆车下可注册多名用户,这将导致同一辆车的驾驶记录并非隶属于一名用户,从而干扰分析。②方法的改进。本文在建模分析时,仅通过数据挖掘方法直观的探究驾驶行为与出险情况的关系,但未对各类驾驶行为进行细分,即各类变量均为独立讨论,而为引入交叉类驾驶行为,在之后的研究中,本文将对变量进一步将其细分,从而将模型进一步精细化。
本文目前的研究为保险公司的UBI车险业务提供了数据分析基础,当该业务付诸实践后,本文将通过实际使用效果进一步对模型进行改进与优化,从多维度而通过UBI车险产品敦促驾驶员改进其驾驶行为,营造安全驾驶的社会氛围。
敬告各位友媒,如需转载,请与统计之都小编联系(直接留言或发至邮箱:editor@cos.name),获准转载的请在显著位置注明作者和出处(转载自:统计之都),并在文章结尾处附上统计之都微信二维码。

发表/查看评论