是的你没有看错,这里真的是一个正经的关于统计和数据科学的网站,本文作者也绝对没有在跑程序的时候偷偷溜去 B 站追番。嗯,大概没有吧。没有吧。有吧。
好吧我必须承认,在当前这个人均 B 站大会员的时代,上 B 站追番刷弹幕已经成了很多90 后中老年前浪们日常的消遣娱乐生活。前不久 B 站买下了《名侦探柯南》的版权,一次性更新到了 1031 集(实际上暂缺 942 到 993 集,所以实际上更新了 979 集)。现在问题来了,1000 多集的《柯南》肯定没法一集一集地看,那么应该如何科学摸鱼规划时间,做到劳逸结合呢?显然,下图给出的建议肯定是不可取的。弹幕里这些一口气肝 1031 集的同学,你们真的是认真的吗?

其实既然是在 B 站,那么必不可少的一项体验就是跟着弹幕一起吐槽越来越飘逸的剧情,比如为什么柯南越来越明目张胆,连麻醉枪都不用就开始推理了,比如为什么过了 1000 多集小兰还是命案现场第一个发出惊呼然后通知警察或者医院的工具人。既然很多剧情已经看过了,那么现在重新追剧的动力似乎就变成了弹幕主打、剧情辅助的观影模式了。于是我有了一个大胆的想法,能不能直接找出弹幕最多的那些剧集,以此作为观影指南呢?
这个目标看上去非常简单,只要点进剧集网页,然后查看弹幕数即可。但别忘了,B 站一次性上传了近 1000 集,即使手速足够快,也要考虑到网速和页面加载的问题。假设一个人可以用 10 秒钟的时间查询到一集的弹幕量,那算下来记录所有剧集的弹幕数差不多也得花三个小时,有这个时间都可以看好几集正片了。
有没有更好的办法呢?当然是有的,毕竟我们号称是数据科学家~~(我不是),每天都在处理海量的数据(我没有),其中第一步的数据收集自然是不在话下了(别瞎说)。由于平时用得最多的编程语言依然还是 R,因此在这里就介绍一些基本的收集 B 站弹幕数据的方法。当然,用 R 的另一个好处是摸鱼不会被发现~~有许多强大的可视化工具可以使用,我会在最后提到其应用。
虽说现在 B 站给大部分人的感觉依然是二次元的聚集地(最近靠《后浪》成功破圈,但争议也远超以往,此为后话),但有一说一,B 站对于开发者还是非常友好的。许多基础的数据,如弹幕、评论、视频基本信息等,都有非常成熟和稳定的应用程序接口(API)可供使用。例如,每个 B 站的视频都具有若干个识别码,像是 AV 号和 BV 号用来构成视频的网址,而视频在弹幕 API 中的识别码一般称为 cid,可以用来查询视频的弹幕信息。如果我们知道了某个视频的 cid,例如 183362119,那么下面的这个网址就会返回该视频的实时弹幕:http://api.bilibili.com/x/v1/dm/list.so?oid=183362119。
你可以试着在浏览器里访问这个网址,它的返回结果不是一般的网页,而是一个 XML 文件。XML 文件也是纯文本,但要从中提取出有用的信息还需要借助一些工具。下面这段 R 代码用到了 curl 和 xml2 这两个软件包,前者用来模拟浏览器访问网址的过程,后者则是去解析得到的 XML 文本。
library(curl)
library(xml2)
api = "http://api.bilibili.com/x/v1/dm/list.so?oid=183362119"
## 获取链接所指内容
ret = curl_fetch_memory(api)
## XML 文本存储在 ret$content 中
doc = read_xml(ret$content, encoding = "UTF-8")
## 获取 XML 中的节点,其中弹幕存储在 <d></d> 标签中
nodes = xml_find_all(doc, ".//d")
danmu = xml_text(nodes)
head(danmu)
[1] "干杯吧!!!!" "这波币值得" "天啊" "十年了!!!!"
[5] "居然能全屏" "哇!!!"
length(danmu)
3000
从中,我们就提取出了 3000 条弹幕。为什么是 3000 这么整的一个数?很遗憾,这是因为 B 站对每一个视频的当前弹幕数都做了限制,比如这个视频其实是《柯南》的第一集,弹幕早就过万了,但新的弹幕会把旧的弹幕挤掉,因此在观看视频的时候最多只能看到3000条,而我们也无法通过公开的方法获取那些已经被挤掉的弹幕。
至此,问题已经解决了一半:只要知道了视频的 cid,我们就可以通过上面的方法获取弹幕数,甚至更进一步,可以获取弹幕的全部文本。那么第二个问题自然就来了:如何知道所有剧集的 cid 呢?其实,方法很粗暴但也很有效:点开《柯南》剧集的网页(https://www.bilibili.com/bangumi/play/ep321808),然后查看页面源代码,我们就会发现如下的一串信息(这里我经过了格式化整理):
[
{
"loaded": true,
"id": 321808,
"badge": "",
"badgeType": 0,
"epStatus": 2,
"aid": 710444604,
"bvid": "BV1PQ4y1N7V8",
"cid": 183362119,
"from": "bangumi",
"cover": "\u002F\u002Fi0.hdslb.com\u002Fbfs\u002Farchive\u002F82d4523e2562748d050a8d8ec7ebc03fbe1a15a1.jpg",
"title": "1",
"titleFormat": "第1话",
"vid": "",
"longTitle": "云霄飞车杀人事件",
"hasNext": true,
"i": 0,
"sectionType": 0,
"releaseDate": "",
"skip": {},
"hasSkip": false
},
...
]
这其实是另一种网页中常见的存储数据的格式,称为 JSON。其中方括号代表了这是一串数组,而每一个大括号包含的内容是一个元素(这里只展示了一条)。只要将这一大串内容存储到一个文件 ep_list.json 中,就可以丢到 R 中进行整理了。在 R 中,可以使用 jsonlite 包读取 JSON 文件并转换成 R 中常见的数据类型:
library(jsonlite)
library(dplyr)
dat = read_json("ep_list.json", simplifyVector = TRUE)
dat %>% as_tibble() %>% select(cid, titleFormat, longTitle)
# A tibble: 979 x 3
cid titleFormat longTitle
<int> <chr> <chr>
1 183362119 第1话 云霄飞车杀人事件
2 183362192 第2话 董事长千金绑架事件
3 183362280 第3话 偶像密室杀人事件
4 183362362 第4话 大都会暗号地图事件
5 183362432 第5话 新干线大爆破事件
6 183362527 第6话 情人节杀人事件
7 183362614 第7话 每月一件礼物威胁事件
8 183362677 第8话 美术馆杀人事件
9 183362762 第9话 天下第一夜祭杀人事件
10 183362916 第10话 足球选手恐吓事件
# ... with 969 more rows
没错,转换的结果是一个数!据!框!Data!Frame!
数据科学家最喜欢的数据格式。
——沃茨基·硕德
于是我们很轻易地从 JSON 文件中获取了每一集的标题和 cid,再结合之前的 curl 访问和 XML 解析,我们便能最后整理出每一集的弹幕量了。
但!是!
凡事都有但是。需要格外小心的是,用 curl 去访问网站是要遵从一定的技术道德的,如果将 curl 包含在一个循环中,那么在循环之间应该使用 Sys.sleep(1) 等命令人为增加一些访问间隙,否则就跟对网站发起攻击没有区别。当然像 B 站这种大型网站都有一些防止频繁访问的机制,比如我之前有一次忘了设置访问间隙,导致本机的 IP 地址直接被 B 站关小黑屋了。为了避免误操作,这里我就不贴详细的代码了,对此感兴趣的同学请参见文末的彩蛋。下面给出最后的部分排序结果,当然这个结果很显然会实时变化,因此只是作展示之用。
# A tibble: 979 x 2
num_danmu title
<int> <chr>
1 3000 第1话-云霄飞车杀人事件
2 3000 第2话-董事长千金绑架事件
3 3000 第3话-偶像密室杀人事件
4 3000 第5话-新干线大爆破事件
5 3000 第6话-情人节杀人事件
6 3000 第7话-每月一件礼物威胁事件
7 3000 第35话-山庄绷带怪人之杀人事件(上集)
8 3000 第51话-图书馆杀人事件
9 3000 第136话-来自黑暗组织的女子 大学教授杀人事件
10 3000 第908话-樱花班的回忆(兰GIRL)
11 3000 第1028话-目标是警视厅交通部(一)
12 3000 第1029话-目标是警视厅交通部(二)
13 3000 第1031话-目标是警视厅交通部(四)
14 2930 第4话-大都会暗号地图事件
15 2903 第78话-柯南对怪盗基德
16 2859 第11话-钢琴奏鸣曲《月光》杀人事件
17 2847 第8话-美术馆杀人事件
18 2803 第1030话-目标是警视厅交通部(三)
19 2676 第138话-来自黑暗组织的女子 大学教授杀人事件
20 2663 第21话-鬼屋杀人事件
21 2577 第10话-足球选手恐吓事件
22 2465 第13话-步美被绑架了
23 2460 第836话-绯色的真相
24 2373 第235话-名侦探齐聚一堂!工藤新一VS怪盗基德
25 2366 第23话-豪华客轮连续杀人事件(上集)
26 2335 第44话-江户川柯南诱拐事件
27 2323 第17话-古董收藏家杀人事件
28 2307 第16话-消失的尸体
29 2303 第22话-电视剧外景队杀人事件
30 2246 第59话-福尔摩斯迷杀人事件(上集)
你是否从中找到了自己的童年阴影呢?不对,你是否通过本文的学习发现奇怪的知识又增加了呢?
最后又到了结尾彩蛋的时间。前面我们介绍了利用 R 中的相关软件包来抓取弹幕的操作,然后只需要再加上亿点点细节,就可以打造出一个实用的追剧可视化工具了。
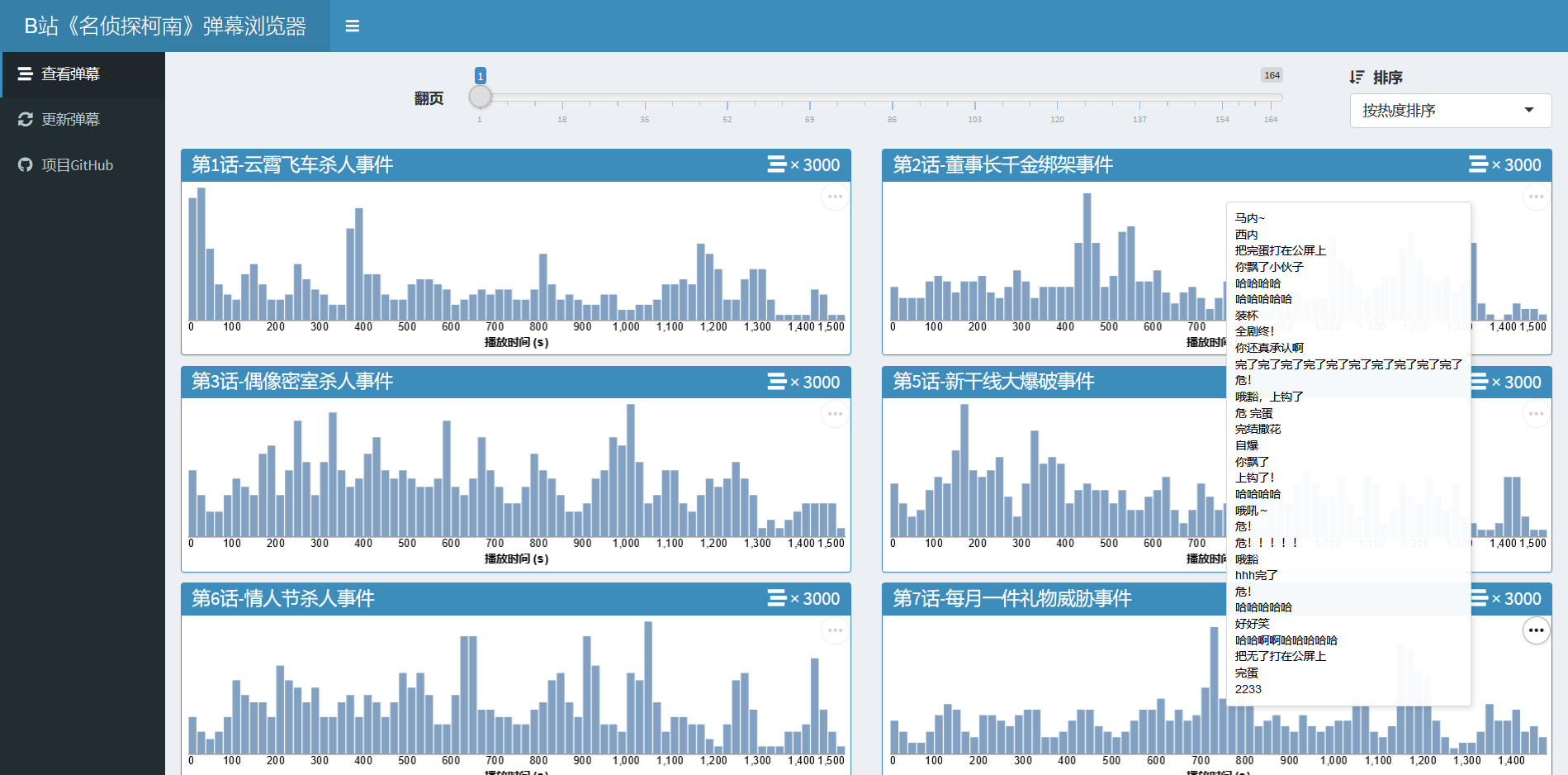
我们用 R Shiny App 来对弹幕信息进行展示,半成品如下: https://yixuanq.shinyapps.io/conan-danmu/。
如果你对这个 Shiny App 的开发感兴趣,欢迎去项目主页(https://github.com/yixuan/conan-danmu)点赞、投币、收藏一键三连……啊不,走错片场了,欢迎大家关注、加星、分支。这个 GitHub 库大致分为两部分,根目录下的几个文件是用来抓取弹幕数据的 R 程序,相当于前文代码的完整版,而 connan-danmu 这个文件夹则是 Shiny App 的源文件,包含了交互可视化的实现方法。最后,B 站还有很多值得去发掘和研究的数据,以后有机会的话再来和大家分享。其实下次也不一定
关于作者
邱怡轩普渡大学统计系博士,卡内基梅隆大学博士后,现为上海财经大学青年教师。感兴趣的方向包括计算统计学、机器学习、大型数据处理等,参与翻译了《应用预测建模》《R语言编程艺术》《ggplot2:数据分析与图形艺术》等经典书籍,是 showtext、RSpectra、recosystem、prettydoc 等流行R软件包的作者。 |  |
敬告各位友媒,如需转载,请与统计之都小编联系(直接留言或发至邮箱:editor@cos.name),获准转载的请在显著位置注明作者和出处(转载自:统计之都),并在文章结尾处附上统计之都微信二维码。

发表/查看评论