统计之都编辑部按:本文是纪念Leo Breiman《统计建模:两种文化》20周年活动的系列文章之一,作者何通。
算法文化的兴起
第一次读到Breiman的经典文章,Statistical modeling: The two cultures [1] 的时候,笔者正处在从统计迁移到机器学习的阶段,读后便留下了深刻的印象,文章发言大胆同时一针见血。当时已经是2010年代,SVM与随机森林如火如荼,深度学习正在抬头,与十年前的成文之时相比,“算法文化”在大众熟悉的应用场景里已经开始慢慢地占据主流地位。
Breiman在文章里吐槽,当时的统计学顶刊文章开头都写着:“Assume that the data are generated by the following model: …”,很多读者现在看到这两句话也都会心一笑,因为这大概是事实,而假设在实际应用里往往不成立也是事实。在计算机流行之前的年代,受限于数据收集与存储的限制,可以说很多情况下这样假设也无可厚非。然而,当数据的复杂程度开始上涨,其内在的生成结构与逻辑可能会变得非常复杂,从而与简单的假设分道扬镳。Breiman为什么与其他的统计学家不那么一样呢?从这篇文章与后续对他的采访来看,Breiman形成提倡算法文化的思路与他极其丰富的咨询经验密不可分。
“诸如第二天洛杉矶盆地的臭氧浓度,高速公路上的一氧化碳浓度,还有一些其他的研究,比如是否能识别出摩尔斯电码是从哪个手机上发送的(这是我们为间谍机构做的事)?或者我们能否通过声呐返回技术识别出潜水艇是俄罗斯的还是美国的?或者我们能否通过雷达回波技术识别出战舰是俄罗斯的还是美国的?”
面对这些问题时,以给出解决方案为导向的人,可不能用 “对不起,你们的数据里有两个变量似乎不是高斯正态分布,还是另请高明吧” 来回答客户。此时,严谨而坚实的统计模型与假设仿佛是在铁轨上开的火车,虽然方向不会跑偏,但是只能在固定的路线上来回。随着数据越来越大,问题越来越复杂,有能力和意愿去收集与分析数据的领域越来越多。大家都看到,从 The two cultures 发表之后,算法文化逐渐开疆扩土,如今已经成为学术圈研究的热点,和许多公司纷纷投资发展的业务核心。
算法文化的挑战
不过,在这样的热潮之下,不少人对算法文化的质疑也慢慢开始了。如果仔细思考算法发展的方向,就会发现它往往需要一个数据集来训练算法,然后评估算法在另一个数据集上的“准确率”作为核心指标。当这另一个数据集确实是任务唯一关心的运算对象时,这样做确实是无可挑剔。然而现实任务往往提出不一样的挑战。
一个大家已经比较熟悉的例子就是对抗攻击:在一张模型能准确识别类别的图片上加上肉眼不可见的噪音,就可以轻松干扰到模型的识别结果。在很多实际应用中,这样的缺陷可能是致命的:比如刷脸支付,智能门禁系统会因此面临攻击,造成经济损失。甚至,自动驾驶的视觉系统会不会受到类似的攻击,进而威胁到乘客的生命?除了对抗攻击这样的主动手段,我们往往会发现一个模型可能还会有别的不经意间的“失效”:
- 更换测试数据集之后,模型就失效了。
- 可能很容易学到训练集里的噪声和偏差。
- 大部分模型依赖于标注,在没有标注或者缺少标注的时候算法往往效果不佳。

图1:一个开源项目[2]的作者成功让神经网络把戴上特制眼镜的自己识别成女明星詹妮弗·洛佩兹。
有人可能会提出,上面这个例子里我们认为模型失效只是因为它没有符合人脑的识别而已,而人脑的识别也只是某一种模型,也有失效的可能,所以模型并不需要完全拟合人脑的结果。也许这个说法的后半段是成立的,但是前半段值得商榷。应该很多人会同意,我们对上述模型做出其失效的判断,更多的是基于物理上的常识:一个人戴上眼镜或者去掉眼镜,并不能改变他的身份。我们的眼睛与算法模型看到的影像不过是这个物理世界的一个投影而已,因为人脑更透彻地理解了投影背后的物理规律,所以它才不那么容易受到投影里的干扰。那么,模型要怎么样才能也学到这样的物理规律呢?

图2:一篇论文[3] 里将奥巴马的低分辨率照片还原到高分辨率时,使他具有了白人的肤色与五官,这在Twitter上引起了广泛的讨论。
我们回过头来想想,其实数据文化本就是以此为出发点来解决问题的:先假设一个生成数据的内在逻辑,再以这个逻辑为基础来定义计算方式与参数,然后通过收集到的数据来训练合适的参数,最后便得到了一个模型。在比较简单的结构上(比如常见的“假设数据服从高斯分布”),统计学家们甚至还能给出这样一个模型各种各样令人满意的性质。然而,现实世界是复杂的,对应的结构也是复杂的,大多数现实的情况下并不能得到漂亮的理论性质。
呼唤新文化
简单的假设有美丽的性质,但是不够实用;完全放弃假设,用数据来驱动模型,又有着新的问题。那么,我们能不能在设计算法的同时加入一些对数据的假设呢? 其实这个做法长久以来都作为算法设计的一个重要的组成部分,但是最近算法的弱点越来越明显,大家对此的关注也逐渐升温。已经有很多学者开始了这方面的探索,尝试提出有针对性的模型,比如:
-
Hinton [4] 提出了一个层次化的假想模型,期望能通过用它从图像中学习到物体中局部—整体关系的算法。除了模型设计本身,这篇文章花了大量的篇幅来讨论这些设计的合理性与局限性,比如层次化模型如何确定层数,如何处理颜色与纹理在不同层级上的意义,如何把一个为图像数据设计的模型迁移到视频数据上等话题。这些设计与讨论实质上都在围绕着数据的性质以及算法对数据性质的合理利用。
-
Yang et al. [5] 利用各个物体的光流方向具有独立性这一假设,不用分割标签便让模型学会了物体分割。这篇文章敏锐地捕捉到了物体之间的独立性会一定程度反映在运动规律的独立性上,而运动规律则会通过光流方向体现出来。基于这一观察,作者提出了一个生成对抗学习(GAN)的训练框架:一个生成模型以原始图像与光流图像作为输入,并输出物体分割的区域;一个判别模型以生成的区域外的光流图像作为输入,预测区域内的光流方向。当物体分割区域被精确预测时,判别模型在独立性条件下则无法通过区域外的光流来预测区域内的光流。
-
Park et al. [6] 利用纹理的局部性,训练了一个生成效果几可乱真的风格迁移模型。作者提出,图像由局部的纹理信息和全局的结构信息组成,在风格迁移时只需要修改局部纹理信息。基于这个假设,作者提出了一个能够解耦局部与全局特征表示的模型,只需要修改局部特征就能生成出结构一样但是纹理不同的图片,从而做到风格迁移。

图3:解耦特征表达[6]便能做到稳健而又真实的风格迁移结果。
也有学者不局限在某个具体模型上,而是对某一个方向进行讨论与展望:
-
Peters and Kriegeskorte [7] 从心理学与大脑视觉的研究出发,讨论了人类在物体识别,补全,组合等任务上的能力,并提出了一些可能能帮助计算机视觉模型的学习与训练的任务;。比如,人有能力把一组物体合并在一起,比如马克杯的杯身与把手,一栋楼的墙体,门与窗户;人的视觉也能对被部分遮挡的物体进行补全。人还会对场景做出解释和期望,当这个期望与事实不符时会感到惊讶,比如看物体突然消失等主题的魔术表演时。这些特性或者能力对目前的计算机视觉系统来说还是比较难以达成的任务。文章花了比较大的篇幅来讨论各个性质能够如何帮助算法设计,希望能启发相关研究者,并最终带来更先进的计算机视觉系统。
-
Sholkopf et. al. [8] 讨论了因果表示学习与机器学习领域的关系,并讨论了一些未来可行的相关任务。文章指出,算法的可迁移性和可扩展性开始成为机器学习研究的痛点与难点,而因果模型能在一定程度上提供帮助,而另一方面,因果推断的研究往往基于因果变量已经给定的前提。于是“因果表示学习”这一方向对机器学习与因果推断都有重要的意义。文章提出了三个相关的任务:学习解耦表示,学习可迁移的机制,学习世界模型来帮助模型进行推理。
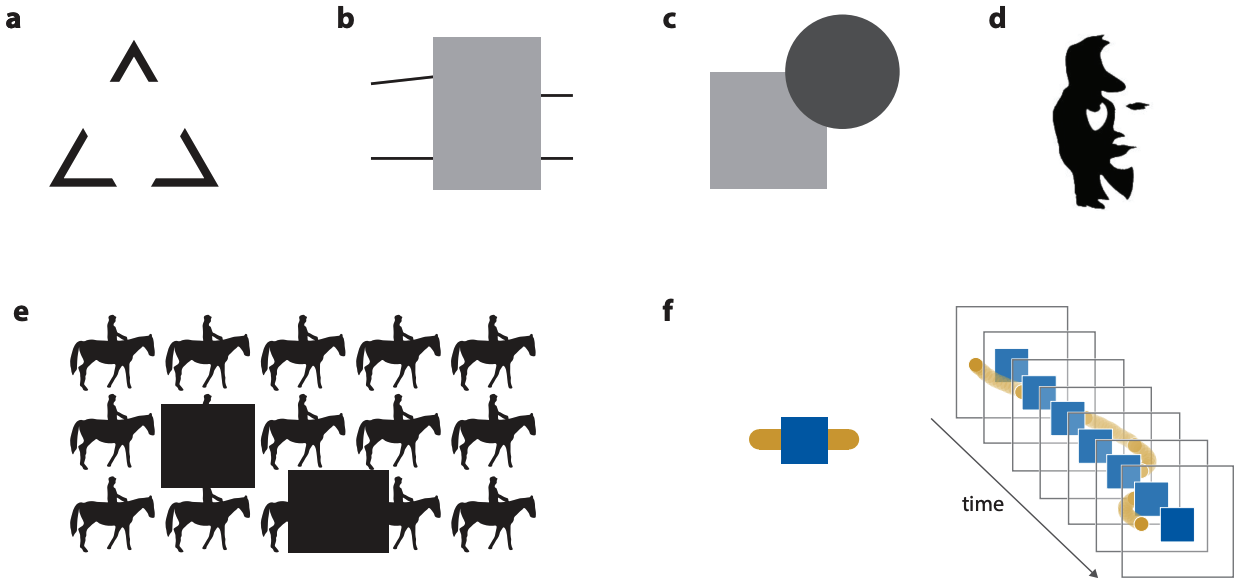
图4:人的视觉能在潜意识里对于只观察到部分的形状/对象进行补全[7],而这个任务对于目前的计算机视觉算法来说还很棘手。
因为笔者比较关注计算机视觉,所以上述例子多与此相关,不过各个领域里数据与模型都越来越复杂是一个不争的事实。因此,我们需要一个新的文化来应对这个新的挑战,而这个新的文化在上述例子中已经有了雏形。从这里孵化出的工作应当首先对数据产生的机制有深刻的理解,同时能够把这个产生机制在计算上表示出来。 这样的表示与经典数据文化里只局限在统计分布上的假设相比,虽然也许更难分析其数学性质,但是也更灵活,从而让使用者能主动针对不同的数据与任务作出不同的合理假设。在这样的表示之上,算法设计往往可以变得更简单,计算效率与数据利用效率可能也更高效。
前文提到的 [6] 便是一个算法设计简单高效的好例子。作者在观察到纹理的局部性之后,在目标风格图像与对应生成图像上分别随机裁剪一个很小的图,然后训练一个额外的小判别模型来判断两个小图是不是来自于同一张图:随机裁剪的小图表示的是局部特征,当生成的图像在局部特征上与目标图像一致,那就已经完成了风格迁移。这正是对数据机制的深刻理解与高效算法设计的完美结合。
图5:更难的挑战需要更强的模型,而更强的模型可能需要一个新的文化作为土壤。
笔者希望这些例子已经能够说明,这个新的文化能把数据文化中对自然规律的理解与算法文化中对计算的优化灵活地结合在一起, 在更多的实际应用中取得成功。这也将模糊“统计学”,“计算机科学”,“数据科学”等领域的界限,各个方面的专家也许都能为这个文化不断丰富成果,进而在面对更复杂的挑战时拿到更坚实的武器。
参考文献
[1] Breiman, Leo. “Statistical modeling: The two cultures (with comments and a rejoinder by the author).” Statistical science 16.3 (2001): 199-231.
[2] https://github.com/jchaykow/AGN-pytorch
[3] https://twitter.com/Chicken3gg/status/1274314622447820801
[4] Hinton, Geoffrey. “How to represent part-whole hierarchies in a neural network.” arXiv preprint arXiv:2102.12627 (2021).
[5] Yang, Yanchao, Brian Lai, and Stefano Soatto. “DyStaB: Unsupervised Object Segmentation via Dynamic-Static Bootstrapping.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021.
[6] Park, Taesung, et al. “Swapping autoencoder for deep image manipulation.” arXiv preprint arXiv:2007.00653 (2020).
[7] Peters, Benjamin, and Nikolaus Kriegeskorte. “Capturing the objects of vision with neural networks.” Nature Human Behaviour (2021): 1-18.
[8] Schölkopf, Bernhard, et al. “Toward causal representation learning.” Proceedings of the IEEE 109.5 (2021): 612-634.
作者介绍
何通,亚马逊资深应用科学家,中山大学统计系本科,加拿大 Simon Fraser University 计算机系硕士。研究兴趣包括计算机视觉,图神经网络,深度生成模型等。在 NeurIPS, CVPR 等会议上发表多篇论文。参与过包括XGBoost, MXNet, DGL等知名开源项目的开发与维护。
关于作者
何通何通,中山大学统计系本科,Simon Fraser University数据挖掘研究生,R包xgboost作者。现任AWS Applied Scientist,为深度学习框架MXNet添砖加瓦。 |  |
敬告各位友媒,如需转载,请与统计之都小编联系(直接留言或发至邮箱:editor@cos.name),获准转载的请在显著位置注明作者和出处(转载自:统计之都),并在文章结尾处附上统计之都微信二维码。

发表/查看评论