准备再尝试一下,用大白话叙述一遍统计推断中最基础的东西(假设检验、P值、……),算是把这段时间的阅读和思考做个梳理(东西不难,思考侧重在如何表述和展示)。这次打算用一种“迂回的”表达方式,比如,本文从我们的日常逻辑推理开始说起。
0.普通逻辑
复习一下普通逻辑的基本思路。假设以下陈述为真:
你打了某种疫苗P,就不会得某种流行病Q。
我们把这个先决条件表述如下:
如果 P 则非 Q
其中,
P 表示打了疫苗P,
Q 表示得流行病Q
或者,更形式化一点:
if P then NOT Q
然后,如果观察到你得了流行病Q,那么就可以推出你没有打疫苗P——这个推断只不过是上述前提条件的逆反命题而已。我们把以上推理过程表述如下:
if P then NOT Q (先决条件)
Q (前提)
———————–
then NOT P (结论)
还有,如果你没有得流行病Q,就能推断出你打了疫苗P吗?显然不能。打疫苗P是不得流行病Q的充分条件,但非必要条件:你没有得流行病Q,可能是因为打了疫苗P,也可以是因为其他任何原因。即,if P then NOT Q,不能够推出if NOT Q then P。
到此为止没有任何令人惊奇的地方。下面将表明,假设检验背后的统计推断规则也只不过是我们以上日常逻辑推理的一个衍生而已。这只需要思维的一次小小的“跳跃”。
1.假设检验
在统计推断中,我们不说“你打了疫苗P,就不会得流行病Q”,而是说,比如,“你打了疫苗P,就有95%的把握不会得流行病Q”,即if P then probably NOT Q。把上面的逻辑推理规则改写成统计推断规则:
if P then probably NOT Q (先决条件)
Q (前提)
———————–
then probably NOT P (结论)
回到以前“万能”的硬币实验,我们做实验来考察一枚硬币是不是均匀的。改写成现在我们熟悉的形式:
P:硬币是均匀的。
Q:在100次投掷中,得到90次正面,10次反面。
我们说,如果是一个均匀的硬币,就不太可能发生这样的情形:投100次,出现90次正面,10次反面(if P then probably NOT Q)。现在如果在100次投掷实验中,观察到出现90次正面,10次反面(Q),那就可以有把握地说,这个硬币不是均匀的(NOT P)。这个推理可以写成与上面一致的统计推断的形式,其中,P是原假设H0,NOT P是备择假设Ha:
H0:硬币是均匀的 (P)
Ha:硬币是有偏的 (NOT P)
如果原假设为真,即硬币是均匀的,就不太可能发生这样极端的事情,比如:在100次投掷实验中,观察到出现90次正面,10次反面(Q)。如果真的观察到这样极端的事情,你就有把握认为硬币不是均匀的,即拒绝原假设(P),接受备择假设(NOT P)。
另外,如果在100次投掷实验中,观察到60个正面,40个反面(NOT Q)。这时你就不好下结论了,因为一个均匀的硬币可能投出这样的结果,一个有偏的硬币也可能投出这样的结果。最后,你只能说,如果实验结果是这样的,那就没有把握拒绝原假设。这枚硬币是否有偏,需要更多的证据来证明(这通常意味着更多的实验,比如,再投1000次)。
总结一下。在搜集数据之前,我们把想证明的结论写成备择假设,把想拒绝的结论写成原假设。之所以写成这个形式,因为从上面不厌其烦的讨论中得知,这是方便逻辑/统计推断的形式:当我们难以拒绝原假设时,只能得到结论,原假设也许是真的,现在还不能拒绝它;而当我们能够拒绝原假设时,结论是:它就很有把握是不真的。注意,在看到数据之前,我们不知道自己想证明的结论是否能够被证据所支持。
在确定假设检验的形式的同时,我们对之前一直随意说的“把握”、“可能”也做一个限定,即指定一个显著性水平α(significance level),也叫犯第一类错误的概率(type I error,在上面的硬币实验中,就是否定一个均匀硬币的错误,也叫“弃真”错误)。
根据某些保守或稳健的原则(比如,我们认为,把一个无辜的人判决为有罪,比放掉一个有罪的人,后果更为严重),我们要尽量把犯“弃真”错误的概率控制在一个很小的水平里。通常α=0.05,这时候就是说,如果拒绝了原假设,你就有95%的把握说原假设是不真的。这里,95%(=1-α)就是置信水平(confidence level)。
又,放掉一个有罪的人,即把一个有罪的人判为无罪,这犯的是第二类错误β(type II error,在硬币实验中,就是把一个有偏的硬币当成均匀硬币的错误,也叫“取伪”错误)。关于第一类和第二类错误之间的权衡取舍(trade off),详见《决策与风险》。在我们的假设检验里,我们认为犯一类错误的后果比犯第二类错误的后果更为严重。
需要注意的是,在这里,我强调的是先提出需要检验的假设,然后再搜集收据。这是统计推断的原则之一。如果看到了数据之后再提出假设,你几乎可以得到所有你想要的结果,这是不好的机会主义的倾向。强调这些,是因为在学校里,我们大多是看了别人搜集好的数据之后再做统计练习。
事先确定好你想拒绝/证明的假设,在看到数据之前,你不知道结果如何。
2.P值(P Value)
上面提到“极端”事件,比如,在100次硬币投掷实验中,观察到出现90次正面,10次反面(Q)。怎么样的事件才是“极端的”?简单地说,一个事件很极端,那么少比它本身“更极端”的事件就非常少(比如,只有“91次正面,9次反面”、“91次反面,9次正面”等情况才比它更极端)。
但这个Q只是从一次实验中得出的。我们可以重复做这个实验,比如100次,每次都投掷100次,记录下的正面数X,它构成一个二项分布,X~B(n,p),其中,n=100,p=0.5。根据某个中心极限定理,正态分布是二项分布的极限分布,上面的二项分布可以由均值为np=50,方差为np(1-p)=25的正态分布来近似。我们在这个近似的正态分布的两端来考察所谓“更极端”的事件,那就是正面数大于90或者小于10。
重复一遍,“P值就是当原假设为真时,比所得到的样本观察结果更极端的结果出现的概率”。如果 P 值很小,就表明,在原假设为真的情况下出现的那个分布里面,只有很小的部分,比出现的这个事件(比如,Q)更为极端。没多少事件比Q更极端,那就很有把握说原假设不对了。
在上述近似的正态分布中,P值就等于X<10 或 X>90的概率值(记做,P{X<10 或 X>90})。根据对称性,这个概率值等于2*P{X<10}=1.2442E-15。
上面我们的确求出了一个非常小的P值,但如何不含糊地确定它就是很“极端”呢? 事先确定的显著性水平α,本身就是一个判定法则。只要P值小于显著性水平α,我们就认为,在认为原假设为真的情况下出现的事件Q,是如此地极端,以至于我们不再相信原假设本身。一句话,我们的判定法则是:
P值小于显著性水平α,拒绝原假设。
3.一个手算示例
用一个双侧的单样本T检验做例子。假设我们想知道,螃蟹的平均温度,跟空气的温度(24.3)有没有统计差别(α=0.05)。事先确定的假设检验的形式表达如下:
零假设(H0): μ=24.3°C
备择假设(Ha): μ≠24.3°C
以下是25只螃蟹在温度为24.3°C下的体温(单位:°C):
25.8 24.6 26.1 22.9 25.1
27.3 24 24.5 23.9 26.2
24.3 24.6 23.3 25.5 28.1
24.8 23.5 26.3 25.4 25.5
23.9 27 24.8 22.9 25.4
一些基本的算术结果:
样本均值:
\(\bar{X}=25.3\)样本量:n=25
样本方差:
\(s^2\)=1.8样本均值的标准误差:
\(s(\bar{X})=\sqrt{s^2/n}=0.27\)
这里T检验的思路如下:
1.我们先假设H0为真,即认为螃蟹的平均温度跟空气温度没有差异(P),μ=24.3°C。有一个极端事件Q,如果原假设H0成立,Q就不成立(if H0 then probably NOT Q);但如果在原假设为真的情况下,出现了这么一个Q,那我们就有把握拒绝原假设。
2.这个样本均值只是一个估计值。它只是从总体的一个随机样本中得到的(样本是上述25只螃蟹)。我们不知道这次实验结果是不是“极端”事件。而判断一个事件是不是极端事件,根据第二节的讨论,我们可以重复做上述实验,比如100次,每次都抓25只螃蟹,都在空气温度24.3的状态下测量其体温,然后也各自求出一个样本均值来。
3.容易得出,这种实验出来样本均值,辅以适当的数学形式,就服从一个自由度为24(=25-1)的t分布,即\((\bar{X}-\mu)/s(\bar{X})\sim t(24)\)。
4.样本均值\(\bar{X}=25.03\),在这个自由度为24的t分布下,有一个对应的t值,t=25.03-24.3/0.27=2.704。现在我们可以在整个分布里考察这个t值。在这个自由度为24的t分布里,我们看 t=2.704是不是一个“极端”事件Q。根据对称性,比Q更极端的是那些大于2.704或者小于-2.704的点。
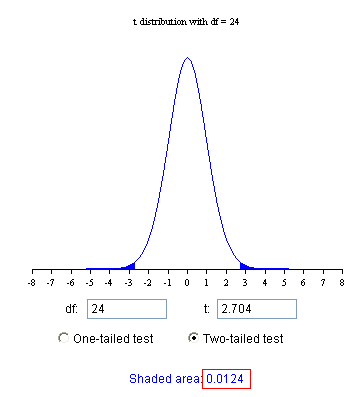
从上图可以看到,在这个t分布里,比t=2.704更“极端”的点占整个分布的0.0124。这个0.0124就是我们要求的P值。这个P值小于我们事先选定的显著性水平α=0.05,因此我们可以拒绝原假设,认为这批螃蟹的平均体温不等于空气温度。
这个双侧P值可以手算如下:
在SAS里,P=2*(1-probt(t,df))=2*(1-probt(2.704,24))=0.012392
在R里,P=2*(1-pt(t,df))=2*(1-pt(2.704,24))=0.012392
———-
以上是用P值作为判定条件。一个等价的做法是用临界值来判断。我们事先给定的显著性水平α=0.05,在这个自由度为24的t分布里,就对应着一个临界t值2.064。下图的阴影部分,也称作拒绝区域。上面求出的跟样本均值\(\bar{X}=25.03\)对应的t值=2.704,处在这个拒绝区域内(2.704>2.064),于是我们一样拒绝原假设。
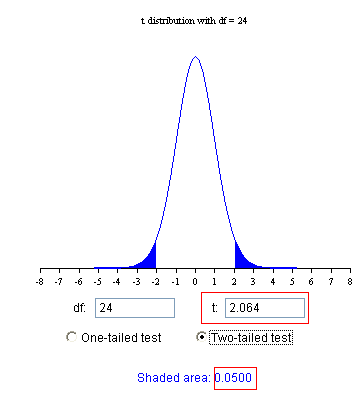
又,上述临界值可以手算(或查表)如下:
在SAS里,tCritic=tinv(1-alpha/tail,df)=2.06390
其中,alpha=0.05,tail=2表示双侧检验,df=24.
在R里,tCritic=qt(1-alpha/tail,df)=2.063899
4.注
本文是对近期阅读做的一个笔记。作为一个非统计科班出身的程序员,我一直在思考,如何来理解统计概念,以及如何把自己的理解向同行传达。关于用日常逻辑推理来理解假设检验的思路,来自
Common Statistical Methods for Clinical Research with SAS Examples(2nd edition, SAS Inc., 2002, by Glenn A. Walker)
关于决策与风险的讨论,参考了
维恩堡《数理统计初级教程》(常学将等译,太原:山西人民出版社,1986,Statistics: An Intuitive Approach By George H. Weinberg and John Abraham Schumaker)
第三节示例的数据,来自
Biostatistical Analysis (5th Edition) by Jerrold H. Zar, Prentice Hall, 2009
第三节的t分布图,来自一个在线的t分布生成器(很好用):
http://onlinestatbook.com/analysis\_lab/t\_dist.html
附录: 用SAS来计算
上面的文字尽量做到“平台无关”。这里附出SAS例子,是想把以上的手算结果跟机器结果做个对照,让读者更有信心一些。 欢迎读者贴出自己趁手的工具得出的结果。
/*data*/
data body;
input temp @@;
h0=24.3;
diff=temp-h0;
datalines;
25.8 24.6 26.1 22.9 25.1
27.3 24 24.5 23.9 26.2
24.3 24.6 23.3 25.5 28.1
24.8 23.5 26.3 25.4 25.5
23.9 27 24.8 22.9 25.4
;
/*method 1: use proc means*/
proc means data=body T PRT;
var diff ;
run;
结果是:
t Value Pr > |t| ——————- 2.71 0.0121
——————-
上面的tValue 就是计算出来的t值,Pr>|t| 就是P值(这里的|t|就是上面计算出来的t值2.704,Pr>|t|求的是比t值更极端的概率,即P值)。proc means没有提供临界t值(即通常说的查表得出的t值),下同。
/*method 2 (prefered): use proc ttest*/
proc ttest data=body h0=24.3 alpha=0.05;
var temp;
run;
proc ttest的结果更为丰富:
N Mean Std Dev Std Err Minimum Maximum
25 25.0280 1.3418 0.2684 22.9000 28.1000
Mean 95% CL Mean Std Dev 95% CL Std Dev
25.0280 24.4741 25.5819 1.3418 1.0477 1.8667
DF t Value Pr > |t|
24 2.71 0.0121
敬告各位友媒,如需转载,请与统计之都小编联系(直接留言或发至邮箱:editor@cos.name),获准转载的请在显著位置注明作者和出处(转载自:统计之都),并在文章结尾处附上统计之都微信二维码。

发表/查看评论